
klustron CDC User Manual
klustron CDC User Manual
Overview
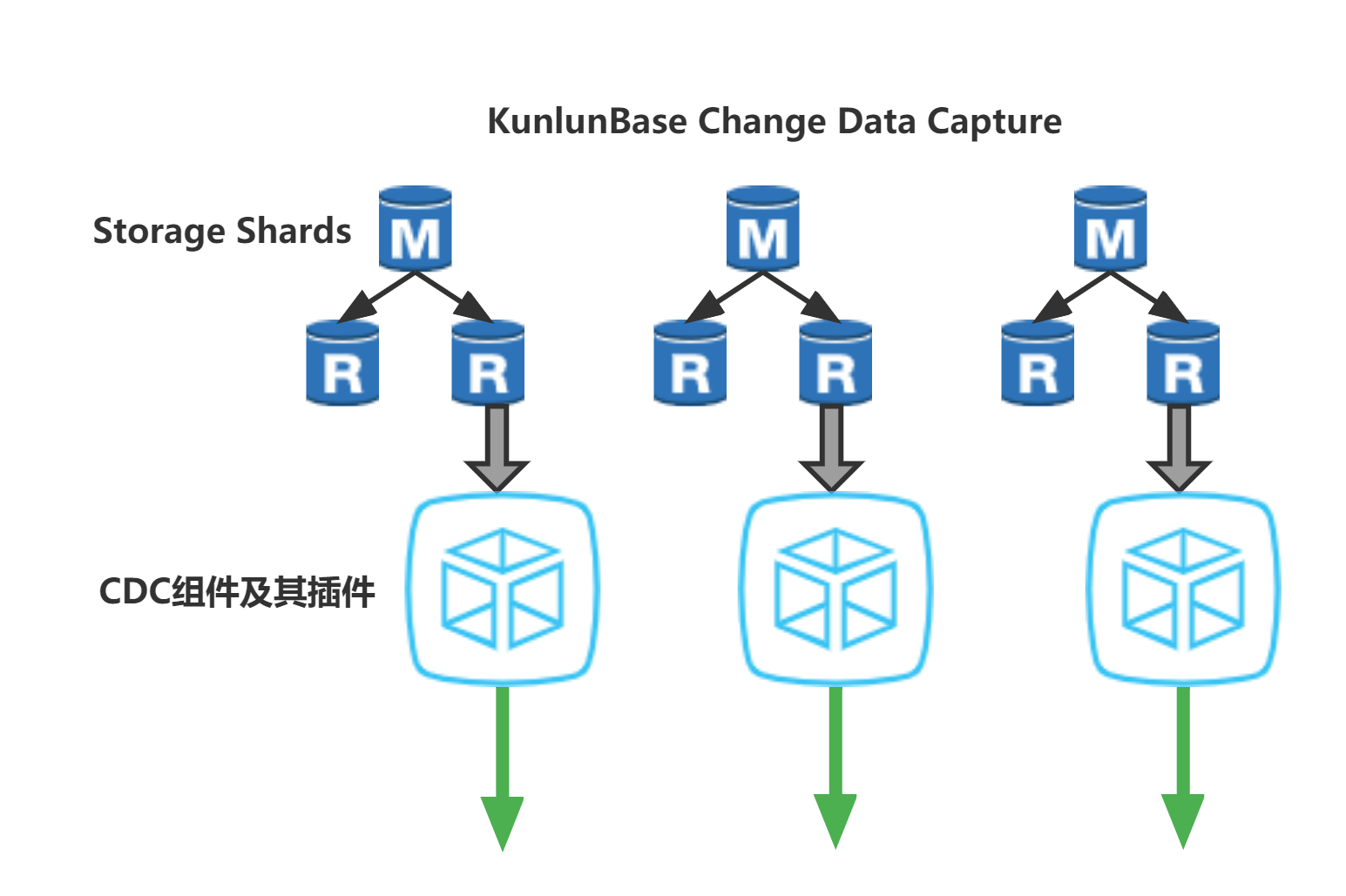
Klustron CDC (Change Data Capture) is used to export real-time data updates from various storage clusters (shards) within the Klustron distributed database cluster as event streams. Each shard has its own event stream, which can be consumed by external components. For instance, external components can perform data stream imports, transferring data updates from Klustron to third-party database systems, or exporting to event stream analysis systems like Flink. Klustron CDC also supports real-time export of data update event streams from third-party open-source MySQL instances, enabling data streaming into the Klustron cluster.
Klustron CDC connects to MySQL or KunlunBase storage nodes to capture and transform real-time data updates using the MySQL binlog dump protocol, then outputs the data in various formats. For MySQL or KunlunBase storage node (Klustron-storage) instances, the Klustron CDC component acts like a replica node. Currently, Klustron CDC supports two modes: exporting data from Klustron clusters and exporting data from open-source MySQL instances.
Features and Usage
Export from Klustron Cluster
Klustron CDC connects to the Klustron metadata cluster based on the dump task parameters and retrieves shard parameters from the Klustron cluster that require data dumping. If there are multiple shards, CDC automatically establishes a dump connection for each shard. Klustron CDC selects the replica node with the least delay in the shard node to perform data dumping. If a primary-to-replica switch occurs during the dumping process due to the current dump node becoming the primary node or the dump node crashing, CDC automatically disconnects the current dump connection and selects another replica node with the least delay in the shard for dumping.
Export from Open-Source MySQL
Klustron CDC connects to the specified MySQL node based on the dump task parameters. For open-source MySQL, CDC continuously monitors the dump connection. If the connection is interrupted during the dumping process due to network issues, the source MySQL killing the connection, etc., CDC automatically reconnects.
Event Output and Transformation Plugins
Klustron CDC utilizes a plugin mechanism to transform and output captured binlog data. Klustron CDC provides an API interface for developing plugins. Users can develop plugins based on the provided API, then attach them to Klustron CDC to process the events generated by CDC. Currently, Klustron CDC comes with two built-in plugins: "event_file" and "event_sql."
The "event_file" plugin stores CDC's output JSON content serialized in a specified file.
The "event_sql" plugin converts CDC's output JSON content into SQL statements and directly sends them to the Klustron cluster or open-source MySQL.
Klustron CDC ensures data integrity when synchronizing data to the target storage. CDC backs up synchronization points in real-time based on dump data GTID information. If the CDC module exits due to various software or hardware failures during the dumping process, it can automatically resume synchronization based on the previous synchronization point when restarted. The CDC module supports cluster deployment for high availability.
To implement other transformation plugins, developers need to follow the plugin interface described below, then attach the plugin to Klustron CDC.
Checkpoint Resumable Data Consistency
Klustron CDC functions as a Raft cluster, with its primary node responsible for event stream processing. If the primary node of Klustron CDC unexpectedly exits, the cluster automatically selects a new primary node to continue working. The new primary node resumes execution from the last saved position before the previous primary node exited. The interval for saving positions can be configured, with a default of 5 seconds. Therefore, to ensure non-duplicate execution of SQL statements, the destination data table must have a primary key. Otherwise, the new CDC primary node might re-execute all operations performed by the previous primary node within the last few seconds before exiting. This could lead to duplicate insertion, deletion, or update of related data rows, causing the destination data to diverge from the source database. This inconsistency might lead to subsequent data synchronization failures and inability to continue the synchronization process.
Event Output Interface Description
JSON Format of Binlog Events Output by Klustron CDC
Klustron CDC outputs each binlog event as a JSON object with the following attributes.
| Field Name | Description |
|---|---|
| gtid | Current event's GTID |
| database | Database name |
| table | Table name |
| isDdl | Whether it's a DDL statement |
| sql | DDL execution SQL statement |
| event_type | Event name |
| data | For insert, it's the inserted data for each column; for delete, it's deleted data; for update, it's the updated row |
| old | For insert, it's empty; for delete, it's empty; for update, it's the data before update |
Binlog Event Types Supported by Klustron CDC
| Field Name | Description |
|---|---|
| CREATE_DB | Create database |
| DROP_DB | Drop database |
| CREATE_TABLE | Create table |
| DROP_TABLE | Drop table; this statement supports multiple tables simultaneously, and kunlun_cdc splits them into separate "drop table" records |
| CREATE_INDEX | Add index |
| DROP_INDEX | Drop index |
| ALTER_TABLE | Alter table by adding, deleting, or updating columns |
| RENAME_TABLE | Rename table; this statement supports multiple tables simultaneously, and kunlun_cdc splits them into separate "rename table" records |
| INSERT | Insert data |
| DELETE | Delete data |
| UPDATE | Update data |
For DDL statements, the JSON field "isDdl" is set to 1, and the "sql" field records the current DDL statement, for example:
{"event_type":"CREATE_TABLE","db_name":"test","sql":"create table t (a int primary key, b int)","isDdl":"1","table_name":"t","data":"","old":"","gtid":"77cf0403-fe85-11ed-87ad-fc3497a73395:5620"}
For DML statements, the JSON field "isDdl" is set to 0, and the specific content is recorded in the "data" and "old" fields. For example:
{"event_type":"INSERT","db_name":"test","table_name":"t","sql":"","isDdl":"0","gtid":"77cf0403-fe85-11ed-87ad-fc3497a73395:5621","data":[{"a":"1","b":"1"}], "old":""}
Custom Plugin Development and Mounting Method
Download the Klustron CDC software from the Klustron official website. In the software package, locate the header file dispatch_event.h required for developing plugins in the include subdirectory.
Inherit the CDispatchEvent class and implement the init, execute, and close virtual functions interfaces. Detailed explanations for each function's usage are provided in dispatch_event.h.
Compile the code into a shared object (so) file on a Linux operating system and place it in the plugin directory of the Kunlun CDC installation package.
In the kunlun_cdc.cnf file located in the conf directory of the Kunlun CDC installation package, add the name of the newly developed plugin under the plugin_so tag.
For example, if the plugin's so file name is event_test.so, add the following content under the plugin_so tag:
plugin_so = event_file,event_sql,event_test
Note: Separate plugin names with commas.
- After modifying the configuration file, you need to restart all CDC processes in the Klustron CDC cluster for the changes to take effect.
Since custom plugins are developed by users, if the plugin requires input parameters, provide those parameters in the output_plugins tag when adding a dump task.
03 Architecture Diagram
04 Configuration and Usage
1. Configuration via API
1.1 Adding Dump Data Tasks (Asynchronous Interface)
1.1.1 Dumping Data from the Klustron Cluster
1> Specify the starting point for dumping from specific locations in the cluster. You need to specify binlog_file, binlog_pos, and gtid_set for each shard in the cluster.
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"add_dump_table",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"meta_db":"172.0.0.1:28001,172.0.0.2:28001,172.0.0.3:28001",
"meta_user":"xxx",
"meta_passwd":"xxxx",
"cluster_name":"cluster_xxx_xxx",
"dump_tables":"postgres_$$_public.t1,postgres_$$_public.t2",
"shard_params":[
{
"shard_id":"1",
"dump_hostaddr":"127.0.0.1",
"dump_port":"28801",
"binlog_file":"xxx",
"binlog_pos":"899",
"gtid_set":"xxxx"
},{
"shard_id":"2",
"dump_hostaddr":"127.0.0.2",
"dump_port":"28802",
"binlog_file":"xxx",
"binlog_pos":"899",
"gtid_set":"xxxx"
}
],
"output_plugins":[
{
"plugin_name":"event_file",
"plugin_param":"/xxx/event.log",
"udf_name":"test1"
},
{
"plugin_name":"event_sql",
"plugin_param":"{\"hostaddr\":\"172.0.0.5\",\"port\":\"24002\",\"user\":\"xxxx\",\"password\":\"xxx\",\"log_path\":\"../log\"}",
"udf_name":"test2"
}
]
}
}' -X POST http://172.0.0.1:18002/kunlun_cdc
2> Start dumping from the current time of adding the dump task.
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"add_dump_table",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"meta_db":"172.0.0.1:28001,172.0.0.2:28001,127.0.0.3:28001",
"meta_user":"xxx",
"meta_passwd":"xxx",
"cluster_name":"cluster_xxx_xx",
"dump_tables":"postgres_$$_public.t1,postgres_$$_public.t2",
"output_plugins":[{
"plugin_name":"event_file",
"plugin_param":"/home/barney/kunlun_cdc/temp/event.log",
"udf_name":"test1"
},{
"plugin_name":"event_sql",
"plugin_param":"{\"hostaddr\":\"172.0.0.6\",\"port\":\"24002\",\"user\":\"xxx\",\"password\":\"xxx\",\"log_path\":\"../log\"}",
"udf_name":"test2"
}]
}
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.1.2 Dumping Data from an Open Source MySQL Cluster
Specify the exact position for dumping data by setting the shard_params parameter. If not specified, the task addition will fail.
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"add_dump_table",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"meta_db":"127.0.0.1:28001", --- dump mysql的ip:port
"meta_user":"xxx", --- User for connecting to MySQL
"meta_passwd":"xxx", --- Password for connecting to MySQL
"cluster_name":"mysql",
"dump_tables":"test.t1,test.t2",
"is_kunlun":"0",
"shard_params":[{
"binlog_file":"xxx",
"binlog_pos":"899",
"gtid_set":"xxxx"
}],
"output_plugins":[
{
"plugin_name":"event_file",
"plugin_param":"/xx/event.log",
"udf_name":"test1"
},
{
"plugin_name":"event_sql",
"plugin_param":"{\"hostaddr\":\"172.0.0.2\",\"port\":\"24002\",\"user\":\"abc\",\"password\":\"abc\",\"log_path\":\"../log\"}",
"udf_name":"test2"
}
]
}
} ' -X POST http://172.0.0.1:18002/kunlun_cdc
1.2 Deleting Dump Data Tasks (Asynchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"del_dump_table",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"meta_db":"172.0.0.1:28001,172.0.0.2:28001,172.0.0.3:28001",
"cluster_name":"cluster_xxxx_xxx",
"dump_tables":"postgres_$$_public.t1,postgres_$$_public.t2"
}
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.3 Getting the Current CDC Cluster Primary Node (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"get_leader",
"timestamp":"1435749309",
"user_name":"kunlun_test"
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.4 Getting Supported Sync Target Plugins in the Current CDC Cluster (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"list_support_plugins",
"timestamp":"1435749309",
"user_name":"kunlun_test"
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.5 Getting All Dump Tasks in the Current CDC Cluster (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"list_dump_jobs",
"timestamp":"1435749309",
"user_name":"kunlun_test"
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.6 Getting the Sync Status of a Specific Dump Task (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"get_job_state",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"meta_db":"172.0.0.1:28001,172.0.0.2:28001,172.0.0.3:28001",
"cluster_name":"cluster_xxx_xxx",
"dump_tables":"postgres_$$_public.t1,postgres_$$_public.t2"
}
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.7 Getting the Status of Asynchronous Tasks (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"xxx", --The job_id of the task you want to query
"job_type":"get_state",
"timestamp":"1435749309",
"user_name":"kunlun_test"
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
1.8 Getting CDC Cluster Configuration Information (Synchronous Interface)
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"list_cdc_conf",
"timestamp":"1435749309",
"user_name":"kunlun_test"
}
' -X POST http://172.0.0.1:18002/kunlun_cdc
2. Configuration via XPanel
2.1 Reporting the CDC Cluster to XPanel
Click on the CDC service and then the "New" button.

Successfully report the CDC service.
2.2 Adding a CDC Task
Click on the CDC task and then the "New" button.
Set up the dump task data source to export from an open source MySQL.
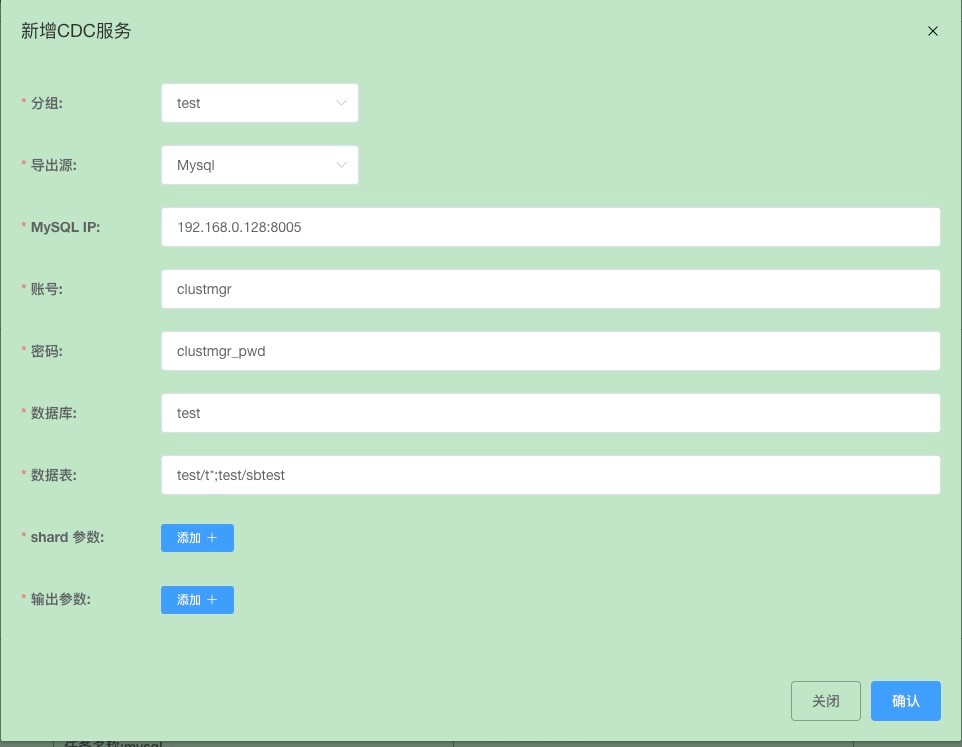
Set up sync point data information.

Click "Confirm" to save.
Configure data sync to the target source; you can configure multiple target sources.
1> Configure data json files.
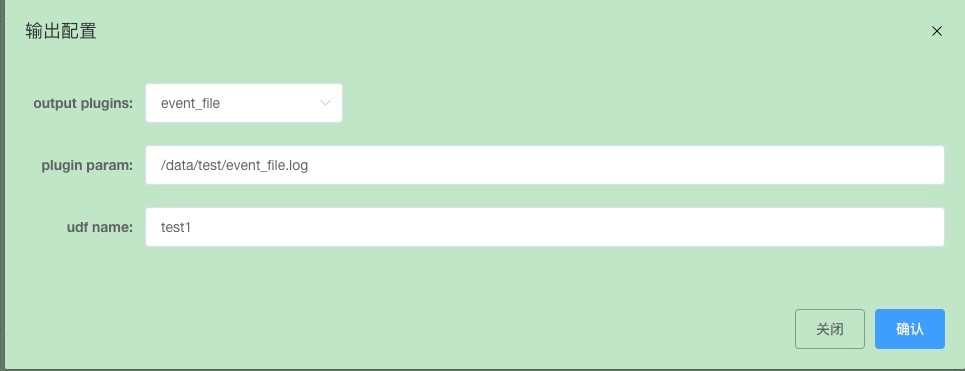
Click "Confirm" to save.
2> Configure sync to Kunlunbase.
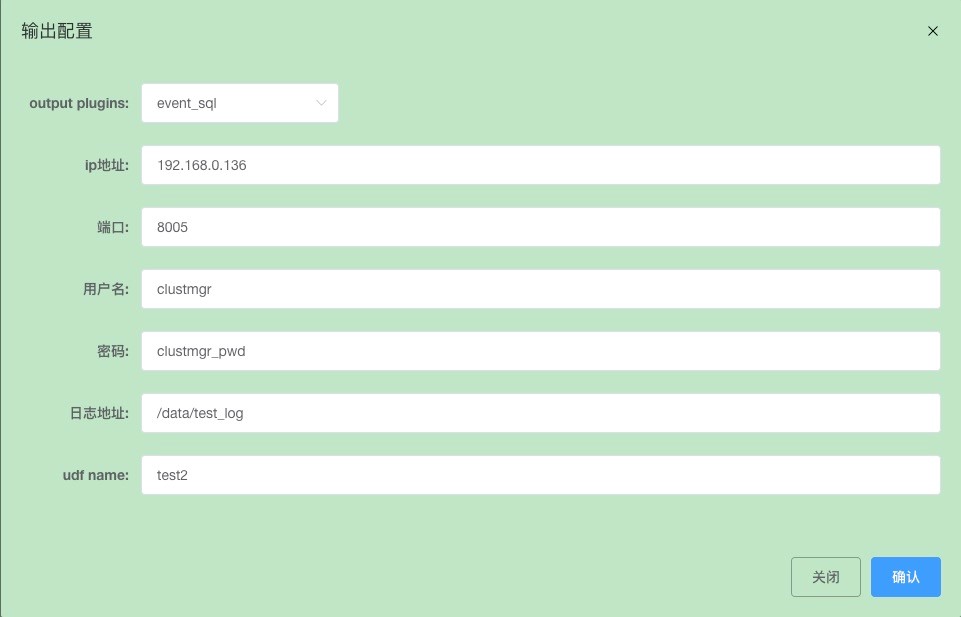
Click "Confirm" to save.
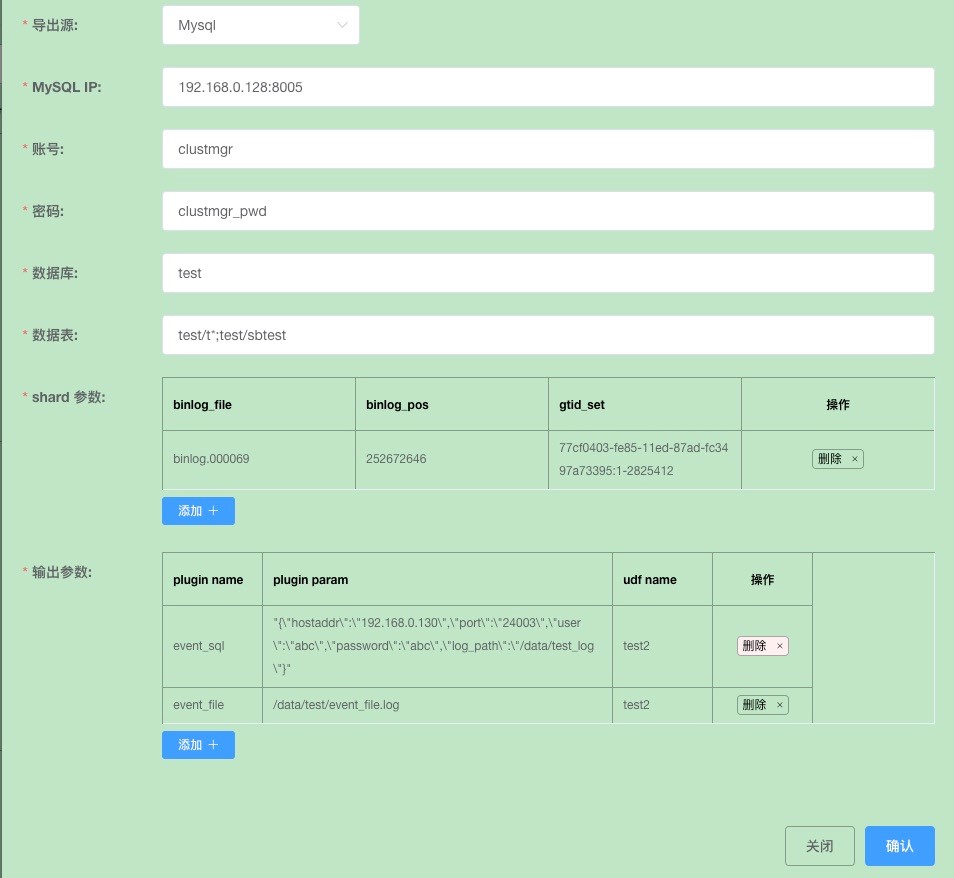
Click "Confirm" to issue the task.
2.3 Deleting a CDC Task
Find the corresponding business from the XPanel CDC task page.

Click "Delete" and enter the verification code to confirm the deletion task.
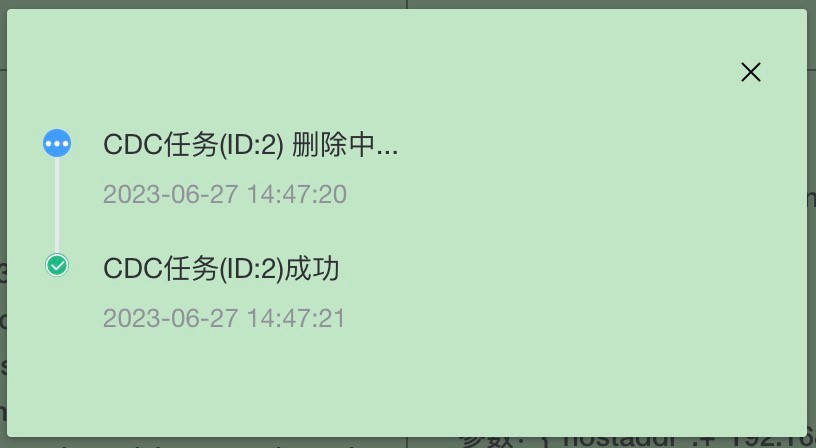
2.4 Viewing CDC Sync Status
Find the corresponding business from the XPanel CDC task page.

Click "Details" to view the specific sync status.
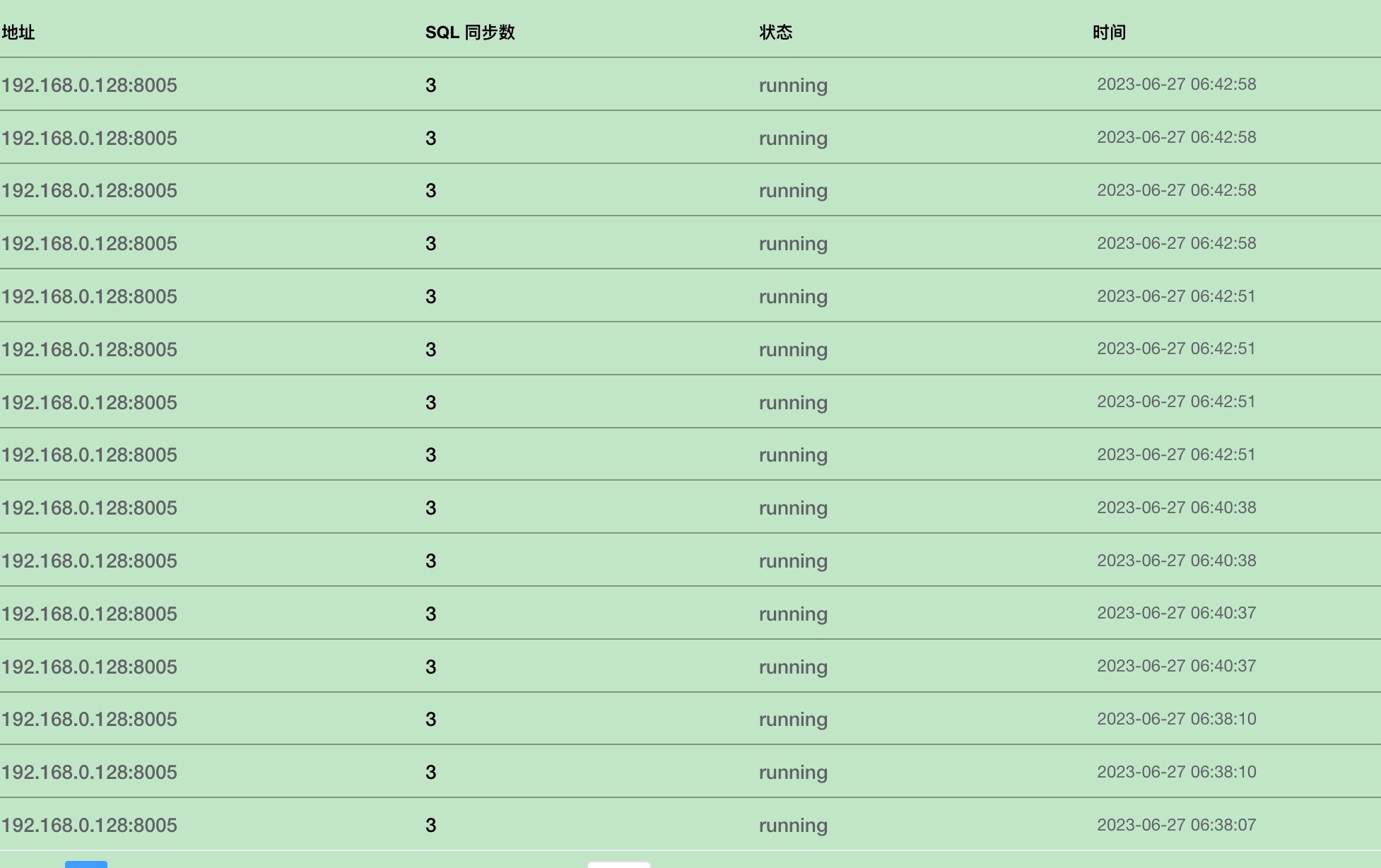
05 Prerequisites for Using Klustron CDC
Configuration required for the source MySQL database for dumping:
gtid_mode=ONto ensure data consistency.binlog_row_metadata=FULLfor proper functioning of CDC.binlog_row_image=FULLis recommended.
06 Built-in Plugin Explanation:
6.1 The event_file plugin directly converts the captured CDC data into JSON and writes it to a file. When developing custom plugins, you can refer to the event_file plugin output.
Input parameters for the event_file plugin are the JSON content to be written to a specific file. Specify these parameters in the output_plugins field when adding a dump task, for example:
"plugin_name": "event_file", -- Plugin name
"plugin_param": "/xx/event.log", -- JSON content is written to this event.log file
"udf_name": "test1" -- Extended field
6.2 The event_sql plugin supports converting the captured CDC data into SQL and writing it to a target database. The target database can be the Klustron cluster or an open source MySQL. It writes to the Klustron cluster by default, but if you need open source MySQL, add is_kunlun=0 to the plugin_param.
Input parameters for the event_sql plugin, specify these parameters in the output_plugins field when adding a dump task, for example:
"plugin_name": "event_sql", --- Plugin name
"plugin_param": "{\"hostaddr\":\"172.0.0.2\",\"port\":\"24002\",\"user\":\"abc\",\"password\":\"abc\",\"log_path\":\"../log\"}",--- Input parameters for event_sql plugin
"udf_name": "test2" --- Extended field
Note: If using event_sql to write source data to a Klustron node, configure the plugin_param with the Klustron computing node's MySQL port, not the pg port.
07 Klustron CDC Deployment Instructions
Obtain the kunlun_cdc installation package and extract it to your target directory.
Go to the conf directory and modify the kunlun_cdc.cnf file.
# Copyright (c) 2022 ZettaDB inc. All rights reserved.
# This source code is licensed under Apache 2.0 License,
# combined with Common Clause Condition 1.0, as detailed in the NOTICE file.
[Base_Config]
############################################
# base config
local_ip = 172.0.0.1
http_port = 18002
log_file_path = ../log/kunlun_cdc
log_file_size = 500
Basic Configuration:
Set local_ip to your machine's IP address.
Specify the http_port for Klustron CDC to listen on.
Configure log_file_path and log_file_size for kunlun_cdc logging.
[Binlog_Config]
############################################
# connect cluster shards strategy
allow_dump_shard_master = 0
dump_shard_node_max_delay = 1800
loop_query_shard_state = 10
loop_report_cdc_sync_state = 5
binlog_msg_queue_len = 1024
pending_binlog_event_num = 1000
reserve_binlog_event_dir = ../data/reserve_dir
kunlun_cdc Dump Binlog Configuration:
Configure allow_dump_shard_master to determine whether dumping from shard masters is allowed (default is 0). This setting is effective when dumping data from the Kunlunbase cluster.
Set dump_shard_node_max_delay to define the maximum allowed delay for dump shard replica nodes. If a node's delay exceeds this value, kunlun_cdc will automatically select another replica node. This setting is effective when dumping data from the Kunlunbase cluster.
Adjust loop_query_shard_state to set the interval for querying the dump shard status.
Set loop_report_cdc_sync_state to specify the interval for solidifying dump table states.
Configure pending_binlog_event_num to determine how many binlog events CDC can cache during XA transactions. When the cache exceeds this value, CDC will write cached binlog event messages to disk.
Define reserve_binlog_event_dir to specify the location where CDC can write cached binlog event messages to disk.
[HA_Config]
############################################
# config paxos
ha_group_member = 172.0.0.1:18001,172.0.0.2:18001,172.0.0.3:18001
server_id = 2
paxosdata_dir = ../data/paxosdata
paxoslog_dir = ../data/paxoslog
paxosdata_compress = 0
paxosdata_write_buffer_size = 2
paxosdata_max_write_buffer_number = 2
paxosdata_min_writer_buffer_number_to_merge = 1
paxosdata_max_backgroup_compactions = 6
paxosdata_max_bytes_for_level_base = 64
paxosdata_target_File_size_base = 64
paxosdata_level0_slowdown_writes_trigger = 12
paxosdata_level0_stop_writes_trigger = 16
paxosdata_block_cache_size = 5
paxosdata_block_size = 64
paxosdata_bloom_filter_bits_per_key = 10
paxosdata_block_based_bloom_filter = 0
Klustron CDC High Availability Configuration:
Specify the ha_group_member as a list of Klustron CDC cluster node IPs and ports, ensuring the number of members is odd.
Set server_id to the position of this node's IP within ha_group_member. For instance, if the machine's IP is 172.0.0.2, then server_id should be set to 2.
[Plugin_Config]
############################################
plugin_so = event_file,event_sql
Klustron CDC Plugin Configuration