
Klustron CDC Parallel Replication and High Availability
Klustron CDC Parallel Replication and High Availability
Note:
Unless specifically stated, any version number mentioned can be substituted with any released version number. For all released versions, please visit: Release_notes
Content of this article:
Previous articles have described the use of the Klustron database CDC module to achieve bidirectional data replication between MySQL and Klustron. In fact, Klustron also has more advanced uses and features. This article will cover two new features: CDC service high availability and CDC parallel replication.
In this article, we will demonstrate these two new functional scenarios.
01 Environment Preparation
The test scenario described in this article involves using CDC for bidirectional replication testing between MySQL and Klustron. Therefore, a MySQL instance environment is needed, as well as a Klustron operational environment. Ideally, this would require four servers—one for MySQL installation and three for the Klustron environment. Due to limited resources, the entire test environment is built using three machines. Since different Linux accounts and different service ports are used, there is no environment conflict.
1.1 MySQL Server Installation and Configuration
Refer to the MySQL Community Edition installation documentation for details (not provided here).
MySQL version: MySQL 8.0.34
IP: 192.168.0.155
Port: 3306
Linux: Ubuntu 20.04.2
Note: To complete synchronization from MySQL to Klustron, MySQL needs to enable binlog (already enabled by default in 8.0) and GTID. The following commands are used to set this up:
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u root -p
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
mysql> SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
mysql> SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
mysql> SET @@GLOBAL.GTID_MODE = ON;
mysql> SET PERSIST GTID_MODE = on ;
mysql> SET PERSIST ENFORCE_GTID_CONSISTENCY = on ;
mysql> SET PERSIST binlog_row_metadata='FULL';
mysql> SET PERSIST binlog_row_image='FULL';
Exit MySQL and restart the MySQL service to make the parameters effective:
systemctl restart mysqld
1.2 Klustron Installation and Configuration
Klustron environment details:
XPanel: http://192.168.0.152:40180/KunlunXPanel/#/cluster
Compute node: 192.168.0.155, Port: 47001
Storage node (shard1): 192.168.0.153, Port: 57005 (Primary)
Storage node (shard2): 192.168.0.152, Port: 57003 (Primary)
Klustron installed under the user 'kl'
1.3 CDC Installation and Configuration
Download the file kunlun-cdc-1.3.1.tgz from http://zettatech.tpddns.cn:14000/dailybuilds/enterprise/kunlun-cdc-1.3.1.tgz and extract it to the 'kl' user's home directory on machines 192.168.0.152, 153, and 155 using the following command:
tar -zxvf kunlun-cdc-1.3.1.tgz
This will create a directory at /home/kl/kunlun-cdc-1.3.1 and related subdirectories.
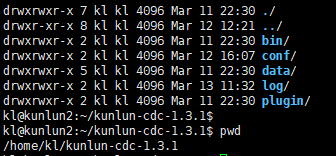
Log in as the 'kl' user and edit the configuration file in the conf directory on machines 192.168.0.152, 192.168.0.153, and 192.168.0.155:
cd /home/kl/kunlun-cdc-1.3.1/conf
vi kunlun_cdc.cnf
Modify the following parameters:
local_ip = 192.168.0.153 # Each machine's own IP
http_port = 18012 # Port consistent across the three machines; can vary as needed
ha_group_member = 192.168.0.152:18081,192.168.0.153:18081,192.168.0.155:18081 # Form a CDC high-availability cluster with these three machines; ports are customizable, this example uses 18081
server_id = 2 # Each machine defines its own ID number; does not need to be unique
Save and exit.
Navigate to the CDC bin directory on the three machines, which contains commands to start and stop the CDC service:
start_kunlun_cdc.sh stop_kunlun_cdc.sh
Execute the following commands on the three machines to start the CDC service:
cd /home/kl/kunlun-cdc-1.3.1/bin
./start_kunlun_cdc.sh
ps -ef |grep cdc
The output will confirm the successful startup of the CDC service.

Log into XPanel at http://192.168.0.152:40180/KunlunXPanel/#/cdc/list, and the following page will open:
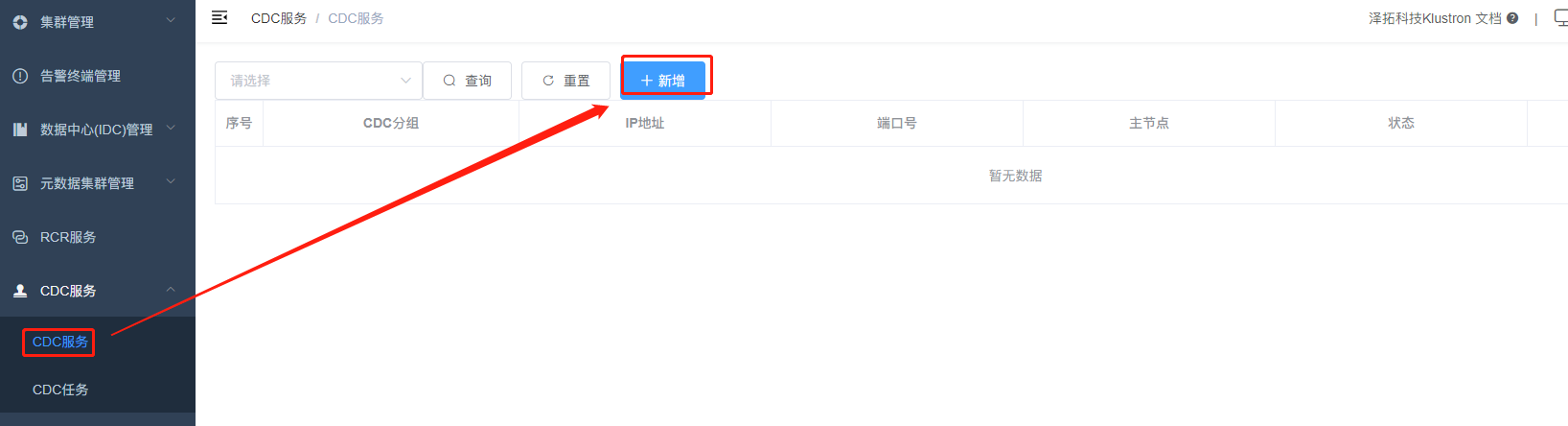
Click “Add” to configure the “CDC service,” enter the corresponding parameters,
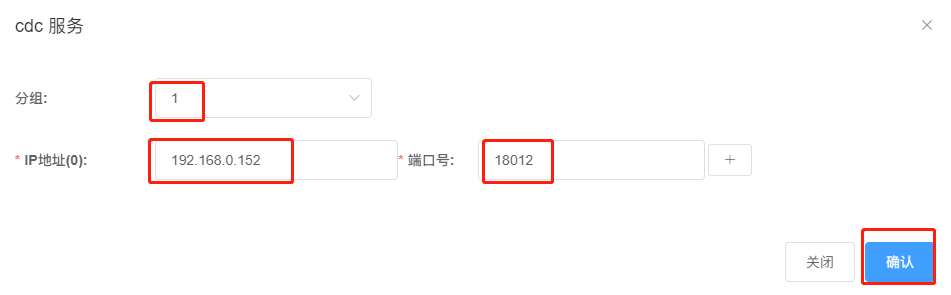
The group number can be customized; in this example, it is set to group number 1. Since three CDC servers form a high-availability cluster in this example, click the "+" sign on the right to continue adding the configuration information for the remaining two CDC services, and click "Confirm" to save.
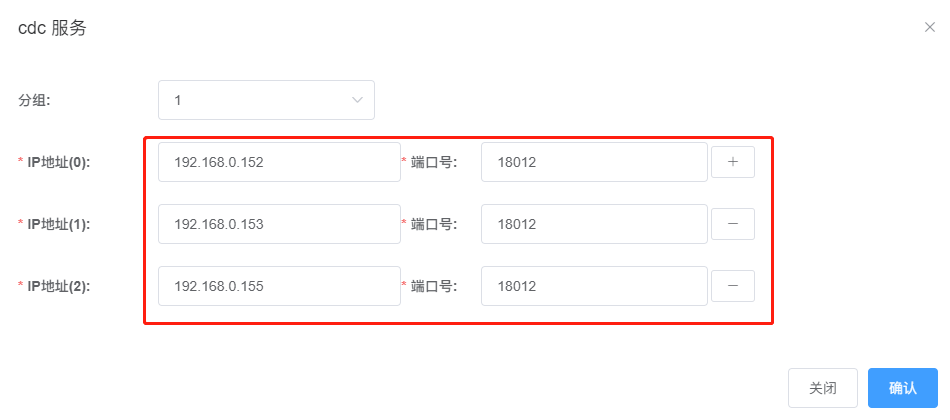
After saving, the interface will look like this:
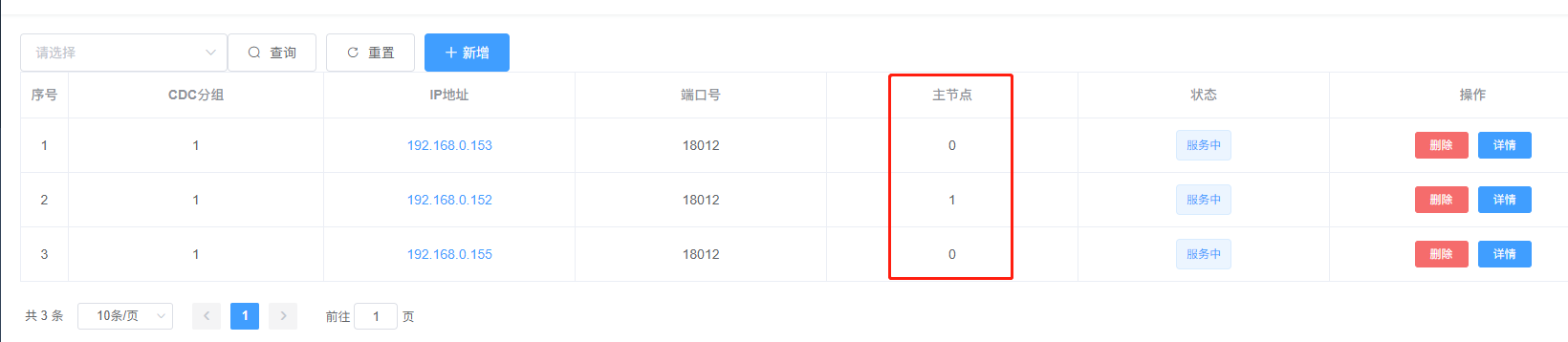
Note: Among them, 192.168.0.152 is displayed as the "main node" in the main node field, meaning it currently hosts the CDC service. The other two nodes serve as backup nodes, and one of them will be promoted to the main node to continue serving CDC-related tasks if the current main node fails.
02 CDC Testing
2.1 CDC High Availability Testing (Verification Scenario: Synchronizing Data from MySQL to Klustron)
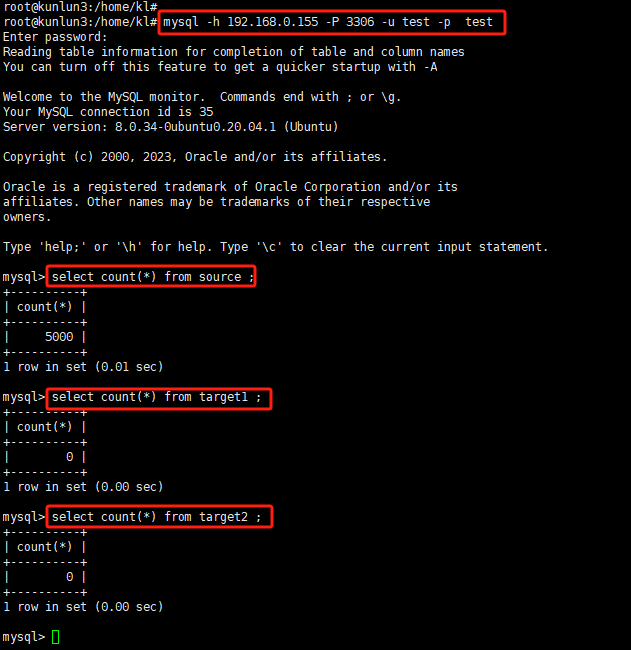
First, establish the corresponding database, user, and tables in MySQL by executing the following commands:
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u root -p
mysql> CREATE USER 'repl'@'%' IDENTIFIED WITH mysql_native_password BY 'repl';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
mysql> create database test ;
mysql> create user 'test'@'%' identified by 'test';
mysql> grant all on test.* to 'test'@'%';
mysql> flush privileges;
mysql> exit;
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql>create table target1 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
mysql>create table target2 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
mysql>create table source (pk int primary key, txt1 text , txt2 text ,txt3 text ) ;
mysql>CREATE TEMPORARY TABLE IF NOT EXISTS series (n INT);
mysql> DELIMITER //
mysql>CREATE PROCEDURE fill_series()
BEGIN
DECLARE i INT DEFAULT 1;
-- Generate 5000 records
WHILE i <= 5000 DO
INSERT INTO series VALUES (i);
SET i = i + 1;
END WHILE;
END //
mysql>DELIMITER ;
-- Invoke the procedure to generate the series
mysql>CALL fill_series();
mysql>truncate table source ;
mysql>INSERT INTO source SELECT n, RPAD('a', 4000, 'a'),RPAD('b', 4000, 'b'),RPAD('c', 4000, 'c') FROM series;
mysql>DROP TEMPORARY TABLE IF EXISTS series;
mysql>DROP PROCEDURE IF EXISTS fill_series;
Connect to the Klustron compute node, establish the corresponding user, schema, and tables by executing the following commands:
kl@kunlun3:~$ psql -h 192.168.0.155 -p 47001 -U adc postgres
create user test with password 'test';
grant create on database postgres to test ;
exit
kl@kunlun3:~$ psql -h 192.168.0.155 -p 47001 -U test postgres
create schema test ;
create table test.target1 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
create table test.target2 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
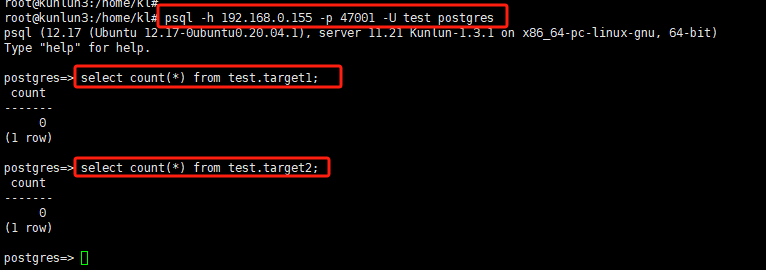
Note: The target tables must have a primary key to ensure SQL statements are not executed repeatedly. Otherwise, the new CDC main node may re-execute all operations from the last few seconds before the previous main node exited, leading to duplicate insertion, deletion, or updating of related data rows. This inconsistency with the source database may cause subsequent data synchronization to fail and be unable to continue.
Open XPanel: http://192.168.0.152:40180/KunlunXPanel/#/cdc/worker, to add a CDC task for data synchronization from MySQL to Klustron:
Click “+ Add” and enter the following parameters:
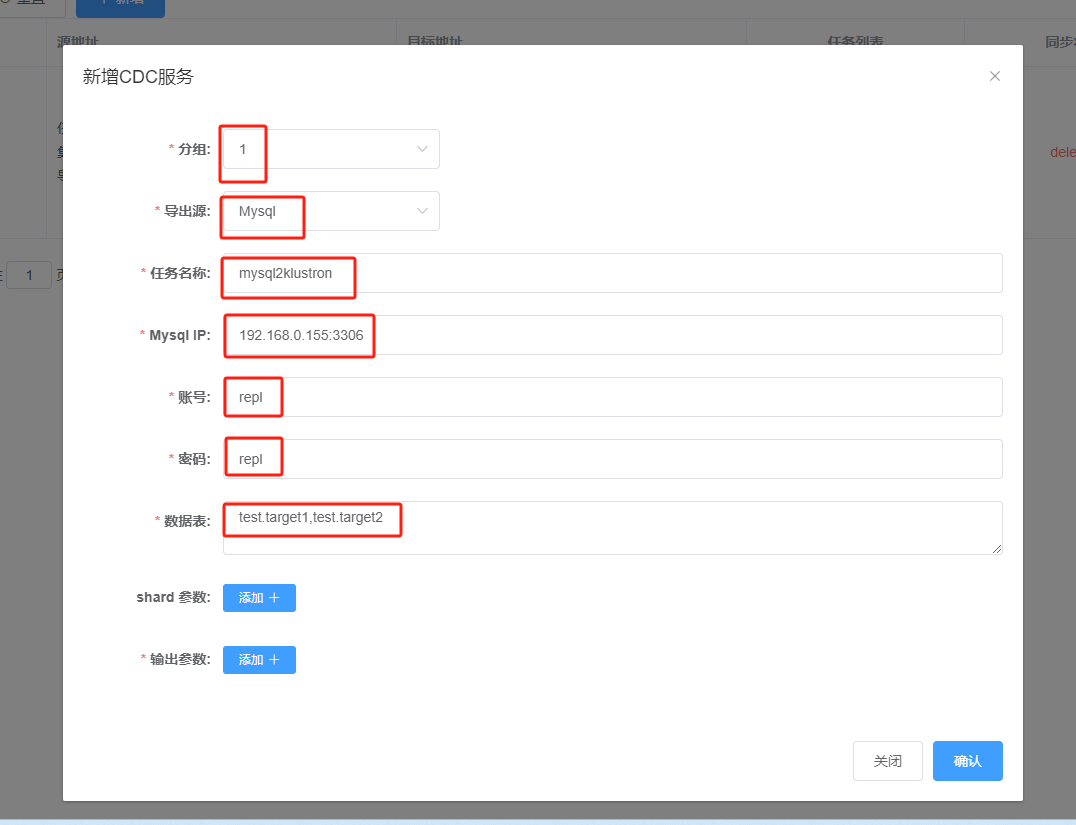
Then, click the “+ Add” next to "shard parameters:" to bring up the following dialog box:
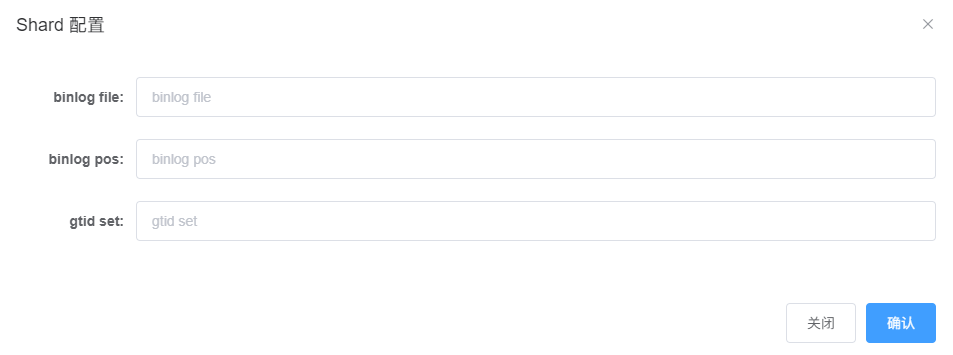
At this point, connect to MySQL and obtain the current parameters for that service instance by executing the following command:
root@kunlun3:~# mysql -h 127.0.0.1 -P 3306 -u root -p
mysql> show master status ;
The output will display as follows:
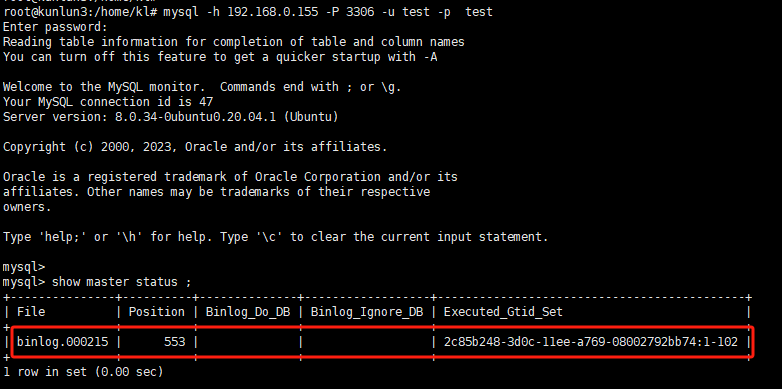
Fill in the file, position, and executed_gtid_set in the previously mentioned shard configuration dialog box as shown:
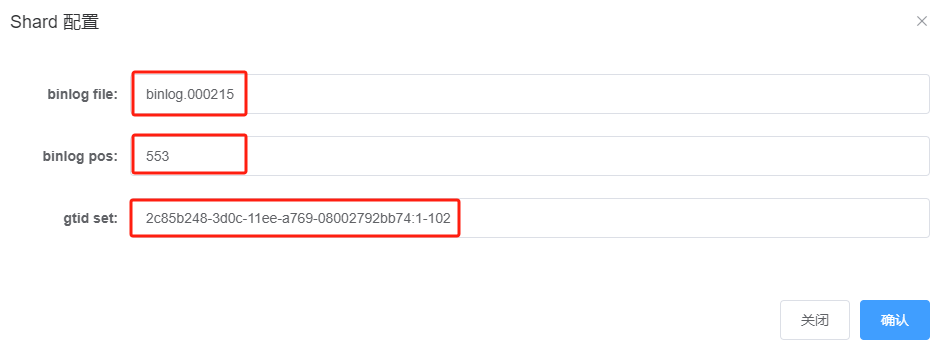
Click “Confirm” to save the configuration information, and continue with “Output Parameters:” configuration:
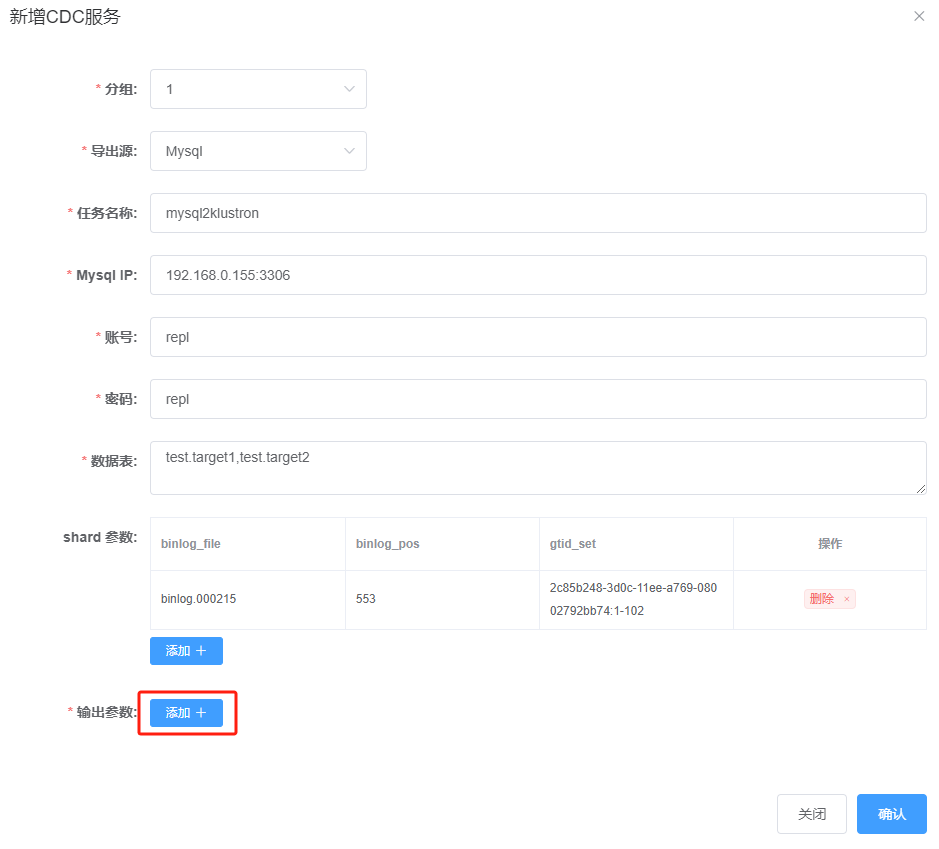
After clicking “Add +”, the following dialog box appears:
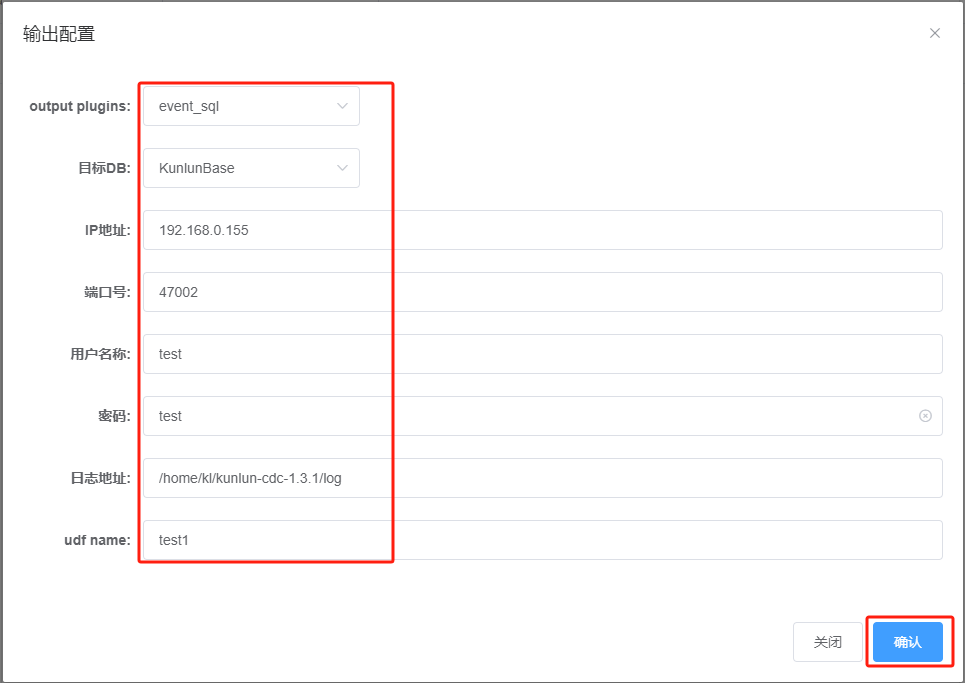
Once these parameters are entered, click “Confirm” to save the parameter settings. The task configuration window will currently display as follows:
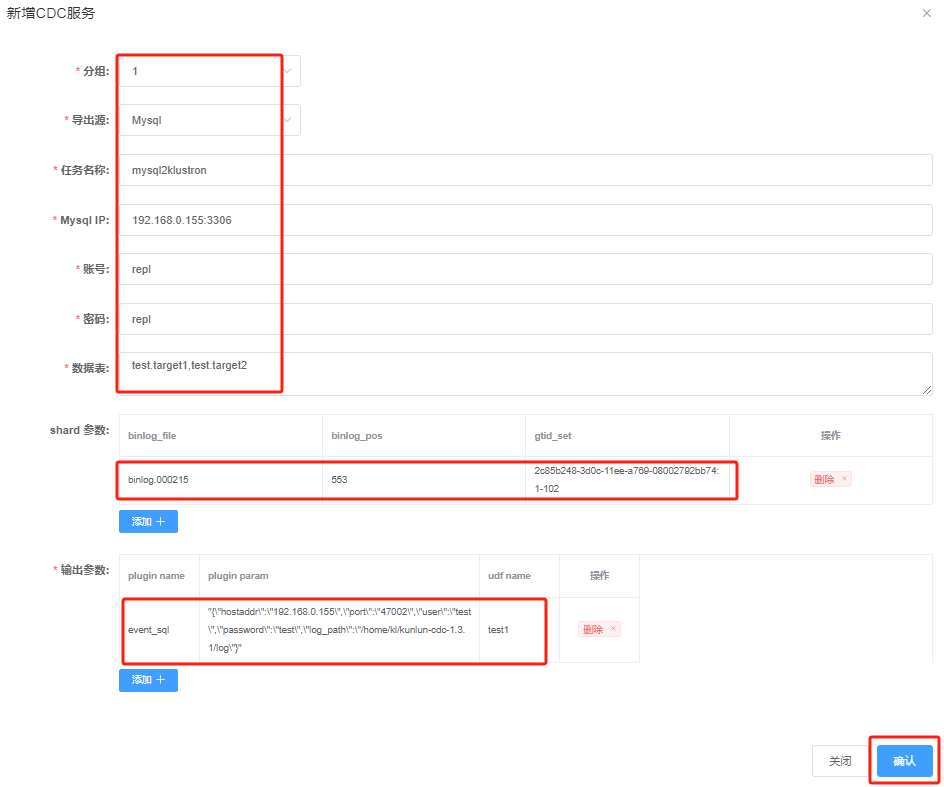
Click “Confirm” again, and XPanel will submit a task for MySQL to Klustron synchronization service, the interface example will be as follows:

If the synchronization task status is normal, we can then proceed with high availability testing during the data synchronization process, which includes the following seven steps:
- Prepare the data verification program on the target side (Klustron side).
- Prepare the data change program on the source side (MySQL side).
- Prepare the command to kill the CDC process on 192.168.0.152.
- Start the data verification program on the target side.
- Start the data change program on the source side.
- Execute the command to kill the CDC process on 192.168.0.152.
- Check if the target side detection program is functioning normally and confirm the results of the data synchronization.
2.1.1 Target-side Data Verification Program
check_data.py # Python2 code format
-------------------------------------------------
import threading
import time
from datetime import datetime
import mysql.connector
config = {
'host': '127.0.0.1',
'port': '47002',
'user': 'test',
'password': 'test',
'database': 'postgres'
}
def check_table(table_name):
connection = mysql.connector.connect(**config)
cursor = connection.cursor()
try:
while True:
query = "SELECT dt FROM %s LIMIT 1" % table_name
cursor.execute(query)
result = cursor.fetchone()
if result:
record_time = result[0]
now = datetime.now()
time_diff = (now - record_time).total_seconds() * 1000.0
print "Table: %s, Time Difference: %d ms" % (table_name, time_diff)
break
else:
time.sleep(0.005)
except mysql.connector.Error as err:
print "Error:", err
finally:
cursor.close()
connection.close()
print "Thread for %s has finished execution" % table_name
thread1 = threading.Thread(target=check_table, args=('target1',))
thread2 = threading.Thread(target=check_table, args=('target2',))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
Code Explanation:
- Connects to Klustron and launches two threads to continuously poll their respective tables for records.
- If records are present, it implies successful CDC synchronization. The time of the record is compared with the current time to calculate the duration of the sync process, which is then printed.
2.1.2 Source-side Data Change Program
run_load.py # Python2 code format
---------------------------------------------
import threading
import mysql.connector
from datetime import datetime
config = {
'host': '192.168.0.155',
'port': '3306',
'user': 'test',
'password': 'test',
'database': 'test'
}
def insert_data(source_table, target_table):
try:
db_connection = mysql.connector.connect(**config)
cursor = db_connection.cursor()
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]
insert_query = "INSERT INTO %s SELECT pk, '%s', txt1, txt2, txt3 FROM %s ;" % (target_table, now, source_table)
cursor.execute(insert_query)
db_connection.commit()
print "Data inserted into %s from %s" % (target_table, source_table)
except mysql.connector.Error as error:
print "Error: %s" % str(error)
finally:
if db_connection.is_connected():
cursor.close()
db_connection.close()
print "MySQL connection is closed for %s" % target_table
thread1 = threading.Thread(target=insert_data, args=('source', 'target1',))
thread2 = threading.Thread(target=insert_data, args=('source', 'target2',))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
root@kunlun3:~#mysql -h 192.168.0.155 -P 3306 -u test -p test
insert into mysql2kl values(1,'aaa');
Code Explanation:
- Connects to MySQL and starts two threads, each inserting 5000 rows into their respective tables (target1, target2) using the insert into select method.
- The tables have wide columns, and the transaction record size is increased to 5000 rows to provide sufficient time to observe the synchronization process and the behavior of killing the CDC process during it.
2.1.3 Prepare CDC Process Termination Command
Connect via SSH to 192.168.0.152 (the current CDC working cluster's current service machine), and at the prompt, enter the following command without executing it:
kl@kunlun1:~$ killall -9 kunlun_cdc
Note: Do not hit enter yet, just prepare the command.
2.1.4 Start the Target-side Data Verification Program
Open an SSH connection to 192.168.0.155 and run the following command at the machine's prompt:
root@kunlun3:/home/kl# python2 check_data.py
The program will poll two tables in Klustron, and upon detecting synchronized data, will output the sync duration and exit.
2.1.5 Start the Source-side Data Change Program
Open an SSH connection to 192.168.0.155 and run the following command at the machine's prompt:
root@kunlun3:/home/kl# python2 ./run_load.py
The program will insert 5000 records into each of the two MySQL tables. Once insertion is complete, it will output information to the console and exit.
2.1.6 Execute the CDC Process Termination Command on 192.168.0.152
In the previously prepared window for the CDC process termination command, press enter to execute the command to clear the process, as shown.

2.1.7 Check if the Target-side Verification Program is Functioning Normally and Confirm the Results of the Data Synchronization
After executing the CDC process clearance task, observe the output from python2 ./check_data.py. After a while, if it outputs synchronization information normally, as shown, this indicates that the synchronization task has completed successfully.
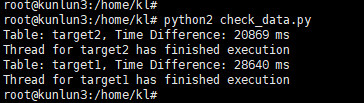
The source-side python2 ./run_load.data will also have completed and exited normally, as shown.
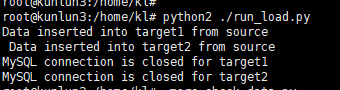
Explanation: This program is designed such that if no data is found in the target tables, it will continue to poll indefinitely without exiting or outputting any information. Therefore, seeing a normal output and completion indicates that the synchronization task has ended correctly.
Next, open XPanel. We can also see that in the CDC service interface, the service status for the machine 192.168.0.152 is marked as "invalid," and the CDC service is now being handled by 192.168.0.153, as shown.
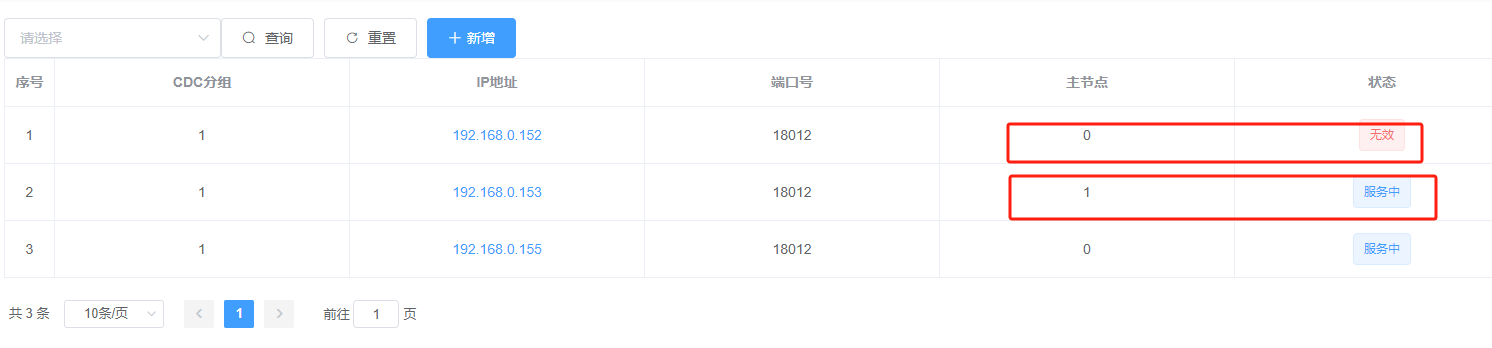
The steps outlined above demonstrate the availability of the CDC high availability service.
2.2 Performance Comparison of CDC Parallel Replication vs. Serial Replication
In the scenario testing CDC service high availability described above, the configured CDC task type used the event_sql plugin type, meaning the CDC task execution was single-threaded. For source-side data changes involving more than one table, the CDC task sequentially completed data synchronization on the target side. Therefore, in the previous tests, we observed that the synchronization time for the table target1 was significantly less than that for target2. We will now perform another test without interruption from the CDC high availability service to observe the duration differences in syncing the two tables, which will serve as comparative data for CDC parallel replication. First, clean the target-side data with the following command:
root@kunlun3:/home/kl# psql -h 192.168.0.155 -p 47001 -U test postgres
postgres=> truncate table test.target1;
postgres=> truncate table test.target2;
Then, clean the source-side data with this command:
root@kunlun3:/home/kl# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql> truncate table target1;
mysql> truncate table target2;
Start the target-side data verification program:
root@kunlun3:/home/kl# python2 check_data.py
Start the source-side data change program:
root@kunlun3:/home/kl# python2 ./run_load.py
After a short wait, the target-side data verification program will exit, outputting the following information:
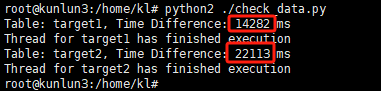
From the data shown, the synchronization of the first table (target1) took about 14 seconds, while the second table (target2) took about 22 seconds, approximately 8 seconds slower.
Before configuring CDC parallel replication, we will first clear the data in the target and source tables again with the following commands:
root@kunlun3:/home/kl# psql -h 192.168.0.155 -p 47001 -U test postgres
postgres=> truncate table test.target1;
postgres=> truncate table test.target2;
postgres=> exit;
root@kunlun3:/home/kl# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql> truncate table target1;
mysql> truncate table target2;
mysql> exit;
Return to the XPanel window, delete the current CDC sync task, and reconfigure it for parallel replication (parallel_sql). Start by clicking the “Delete” button to remove the current task, as shown:

After following the prompts and confirming the deletion, click the "Confirm" button:
The task is now deleted:
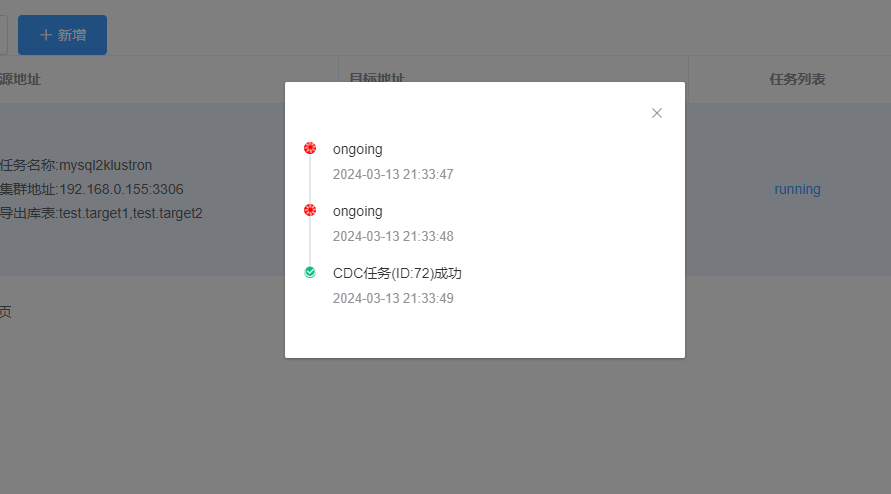
Click “+Add” again to configure a new CDC task:
For brevity, the detailed configuration process is not repeated here; just note the parameters in the following configuration screen:
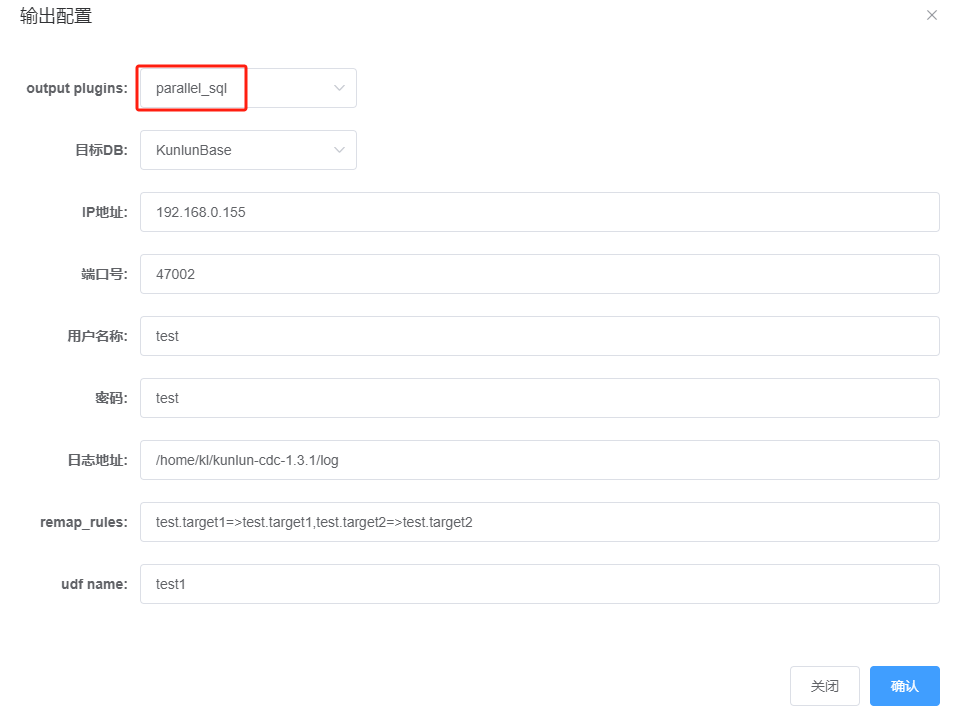
Specifically, choose the "parallel_sql" for the CDC plugin type. After completing the CDC task configuration, the following data synchronization task is added in XPanel:

Start the target-side data verification program:
root@kunlun3:/home/kl# python2 check_data.py
Start the source-side data change program:
root@kunlun3:/home/kl# python2 ./run_load.py
After a short wait, the target-side data verification program will exit, outputting the following information:
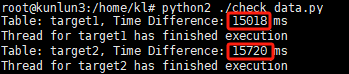
From the data shown, the synchronization of the second table (target2) finished less than a second slower than the first table (target1). Compared to the previous single-threaded serial synchronization where there was an 8-second difference, using the CDC parallel replication task this time significantly improved the performance from source to target. This demonstrates that CDC sync tasks, particularly in high-concurrency application systems requiring synchronization of multiple tables, should prioritize using CDC parallel replication.