
Why Does the Replica Lag Graph Resemble a Right-Angled Triangle?
Why Does the Replica Lag Graph Resemble a Right-Angled Triangle?
In a mature database management system, monitoring is essential. In a high-availability architecture, there is at least one standby replica, the purpose of which is to switch to the replica in case the primary node becomes unavailable, enabling quick service recovery. The situation of replica lag determines the switchover time of the HA system, making monitoring of replica lag equally indispensable.
The ideal replica lag monitoring graph is a function graph with y = 0, indicating that the replica node consistently exhibits no lag (or lag less than 1 second).
For a primary node with high update transactions per second (TPS), even occasional spikes of 1-second lag are considered quite reasonable.
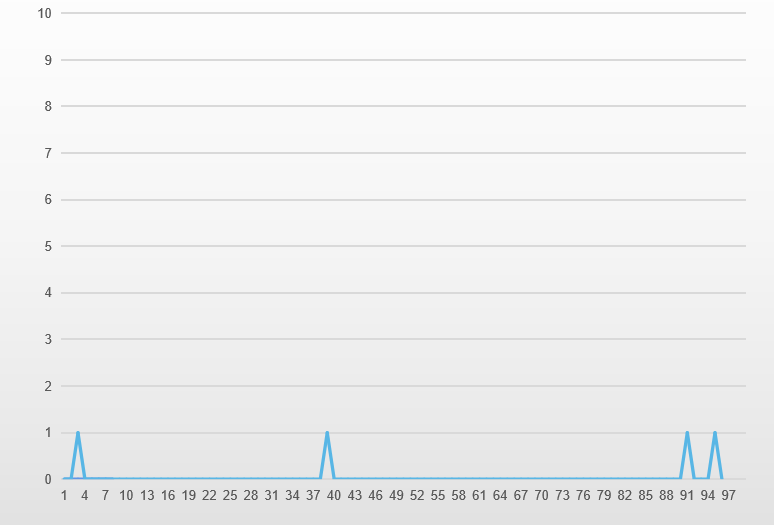
This graph illustrates that occasional lags of up to 1 second may occur but quickly catch up.
Another typical replica lag graph depicts a right-angled triangle, as shown below.
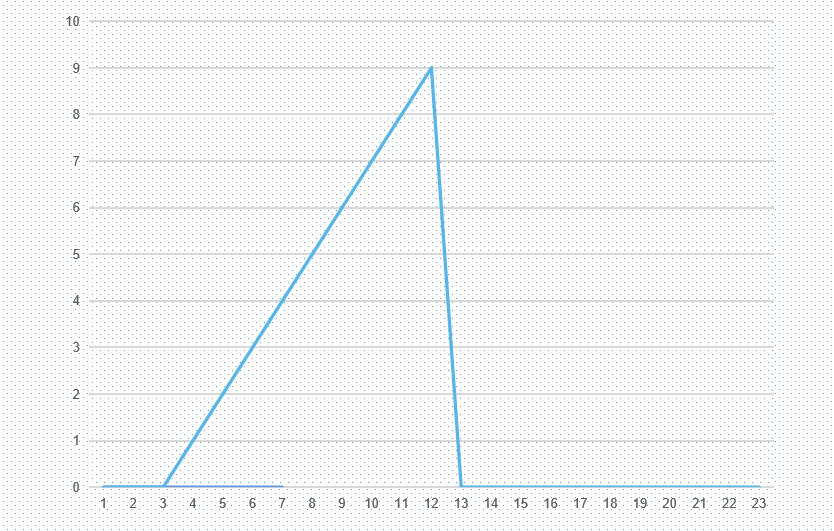
From the third second onward, the lag increases by 1 second every second until it suddenly disappears at the thirteenth second. The most common reason for this is when the primary node executes a large update, such as updating a substantial amount of data within a transaction or executing a DDL statement.
This transaction takes 10 seconds to execute on the primary node and another 10 seconds to apply on the replica. During the application of this transaction on the replica, the observed lag graph shows a continuously increasing delay each second.
This lag issue is largely unresolved under the existing MySQL binlog mechanism.
This raises a question: Why is it that the redo log can be written while being executed in a transaction, whereas the binlog cannot?
During transaction execution, it's possible to concurrently execute and write to the redo log (redo log buffer) due to its nature as a physical log recording modifications to data pages. However, the binlog (binary log) is a logical log that records SQL statement behaviors. During runtime, modifications to physical pages are written to the redo log buffer when executed and later flushed to disk by transaction commits or dedicated background threads.
In contrast, the binlog needs to be durably persisted to disk upon each transaction commit to enhance performance and recovery speed. If the binlog were also written concurrently during execution, it could result in interleaved recording of binlog entries from different transactions, causing them to be "mixed."
Interleaved binlog records from different transactions can lead to logical issues when executed downstream, such as on replica databases or other receivers parsing binlogs.
Hence, binlog entries on the primary node must be written one by one in a complete and uninterrupted manner.
For a large transaction that updates multiple rows, allowing it to continuously occupy the binlog would affect the commits of other transactions. Consequently, each transaction must have its own log cache. During transaction execution, the log is first written to the thread's own binlog cache. All transactions go through a three-phase pipeline, with the flush phase involving groups of transactions being flushed to the binlog file together, along with the ongoing commits, during the same flush phase.
From the above analysis, it's apparent that a transaction executed on the primary node for 10 seconds would result in a 10-second delay on the replica. While it might seem unsolvable, there is, in fact, an optimization opportunity here.
While the transaction log is being written from the binlog cache to the binlog file, the I/O thread of the replica is in a waiting state. This is because the primary node begins sending the binlog to the replica only after the binlog for each transaction is completely written. This is the community edition's implementation.
In practice, since there are no other logs being written on the primary node at this time, it's possible to send the binlog entries to the replica while they are being written, reducing the replica's waiting time. Essentially, as soon as the primary node's binlog cache write is completed, the replica has received most of the transaction log and can start applying it. This can help reduce the replica's latency.
The Klustron team has implemented this optimization, and now let's analyze whether this optimization introduces new problems: During the period of binlog cache writing to binlog files and when the replica has already received some of the binlog entries for the ongoing flush, would there be issues if the primary node experiences an unexpected crash?
Let's start by examining the primary node. After the primary node restarts, due to incomplete logs in the binlog file, the crash recovery process will roll back the affected transaction. If this transaction is an XA transaction, the community edition of MySQL cannot perform correct fault recovery for it, while Klustron-storage can correctly recover such transactions.
On the replica node, in the community edition, there isn't even partial log of this transaction available. In our optimized version, the replica has partial log entries for the last transaction, but these are also incomplete. When the log application thread on the replica executes this transaction and reaches the incomplete portion, it will roll back the transaction halfway. In essence, the replica also lacks this transaction, resulting in behavior consistent with the community version.
In another scenario, if the primary node has completely written the logs but the replica has not finished receiving them and the primary node experiences a crash and restarts, upon the replica reconnecting to the primary node, it will completely fetch the entire binlog of this transaction and execute it.
As a side note, there is a bug in the community edition MySQL 5.7 version: When the replica's I/O thread starts receiving the binlog of an ordinary transaction (begin...commit), and simultaneously the replica's worker thread starts replaying the same transaction, if the I/O thread's connection to the primary node is disconnected for various reasons (such as primary node failure), causing the replica not to completely receive the transaction, then the replica's worker thread will roll back the transaction. However, if this transaction is an XA transaction, the community edition MySQL 5.7 cannot correctly roll it back, while MySQL 8.0 can.
In the next version of KunlunBase, we will use an entirely new technological approach in Klustron-storage to fully address the issue of MySQL's inability to transmit binlog entries concurrently with their generation, which leads to increased primary-to-replica delay during the execution of large transactions. This will effectively resolve the issue of increased delay caused by the substantial binlog data volume generated by transactions, thereby further enhancing KunlunBase's high availability capabilities.