
Issues with MySQL Distributed Transaction Processing and Solutions by Kunlun-storage
Issues with MySQL Distributed Transaction Processing and Solutions by Kunlun-storage
This article delivers an in-depth exploration of a crucial aspect of KunlunBase's financial-grade high reliability technology framework -- the Kunlun-storage's node failure recovery mechanism. It's important to note that a deep understanding of this article's content isn't necessary for effective use of KunlunBase; it primarily serves as a reference and study guide for those interested in the core technology of KunlunBase and the mechanics of MySQL transaction processing.
MySQL community edition lacks support for failure recovery of XA transactions, which prevents it from being directly used as a storage node within a distributed database. Kunlun-storage has improved and enhanced MySQL's transaction recovery mechanism, most notably by introducing a failure recovery mechanism for XA transactions. This innovation serves as the basis for the KunlunBase cluster's failure recovery process and is a key component of the KunlunBase core technology system.
Following the improvements and enhancements to the MySQL community edition transaction failure handling detailed in this article, a KunlunBase cluster, built on Kunlun-storage, can adeptly manage any node failure within its structure. Moreover, it guarantees the ACID properties of all transactions successfully committed within the KunlunBase cluster, thereby assisting KunlunBase in achieving financial-grade high reliability.
This article first provides a snapshot of the KunlunBase products and technical architecture, before delving into the KunlunBase cluster's failure recovery technology. These topics are thoroughly addressed in other articles. It then describes the failures that distributed database clusters might encounter and the potential harm if not suitably resolved. The article further explains the fundamentals and critical techniques of MySQL transaction processing, as well as its failure handling and transaction recovery technology. Special attention is given to MySQL's shortcomings and vulnerabilities in handling XA transactions and how KunlunBase addresses these issues.
An Overview of KunlunBase's Failure Recovery Technology
The Two-Phase Commit Process of KunlunBase Distributed Transactions
To facilitate understanding, let's initially explain the technical terminology associated with the two-phase commit algorithm. A global transaction (GT) executes transaction branches (LT) across several storage nodes, a.k.a resource managers (RM), with its status and commit process managed by the global transaction manager (GTM). In MySQL, transactions eligible to act as distributed transaction branches are referred to as XA transactions. Specific SQL commands are used to manage these transactions, including XA START, XA END, XA PREPARE, and XA COMMIT [ONE PHASE]. These XA transactions stand in contrast to regular transactions, which are initiated and committed through the "begin...commit" sequence, and the Create-Read-Update-Delete (CRUD) transactions under the "autocommit" setting.
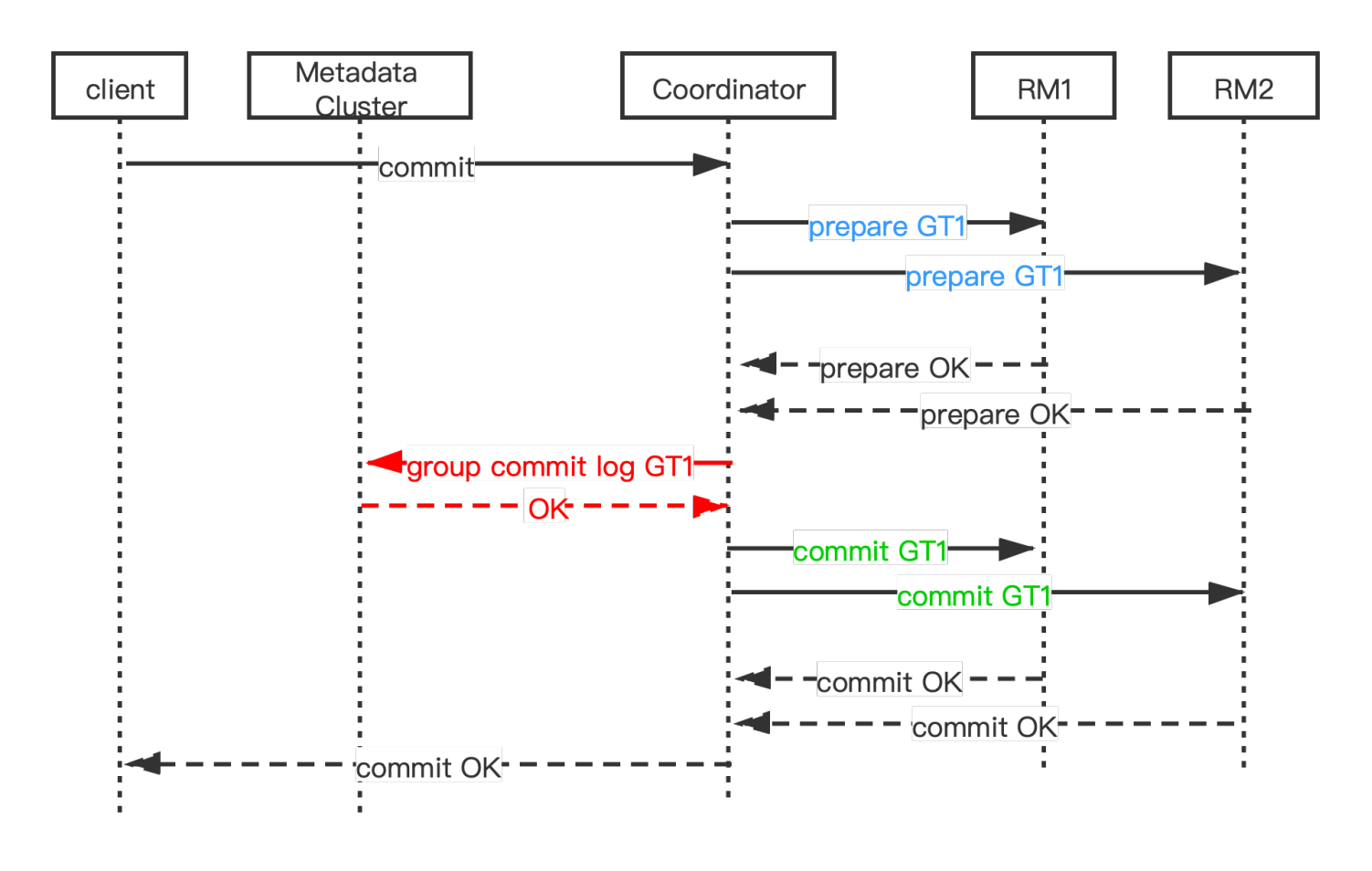
Illustration of the Two-Phase Commit Process of KunlunBase Distributed Transactions
In KunlunBase, when a transaction that writes to multiple shards is committed, the Global Transaction Manager (GTM) residing in the compute node initiates a two-phase commit (2PC), the methods and process of which can be found in this article.
In general, the two-phase commit is designed to prevent issues that arise when multiple RMs try to commit transaction branches, and some fail to commit successfully. Only after the first phase (PREPARE phase) has been completely successful does the process advance to the second phase (COMMIT phase). If any RM fails during the PREPARE phase, the GTM instructs all the RMs involved in that global transaction to roll back their transaction branches. Only when all RMs have succeeded in the first phase, the GTM initiates the COMMIT phase. Should any RM or compute node experience a failure during this phase, KunlunBase's cluster_mgr takes over, managing all global transactions that were in the midst of the commit process at the time of failure. This means all transaction branches are either fully committed or entirely rolled back.
Potential Failures in Database Clusters and Their Risks
In any distributed cluster made up of computer servers, there is potential for numerous types of failure. These can include server power outages or hardware/software malfunctions (e.g., hardware device failure, OS crash, human error, scheduled maintenance; system overload, depletion of internal or external storage space, exhaustion of other system resources), network disruptions (e.g., network partition, network congestion), or even total data center collapse (e.g., natural disasters, severed fiber optic cables).
For KunlunBase, any of these failures could lead to interruptions in the execution or commit process of a global transaction. If a storage node encounters a failure, it could also disrupt the commit process of regular or XA transaction branches. If these disruptions are not correctly managed, a variety of problems may arise. Specifically, a failure that occurs during the 2PC process of a global transaction could result in:
- Gradual System Shutdown
Should a compute node or storage node fail, there may be residual XA transactions left in the PREPARED state. Since these transactions still hold transaction locks, they can block other active transactions that conflict with these locks. These blocked active transactions may also hold transaction locks, leading to an even larger number of active transactions being blocked. Eventually, this causes the database system to gradually halt normal operations and service provision.
- Partial Commit and Rollback of Transaction Branches
This could result in a partial loss of data updates, thereby causing data inconsistency and corruption, which is a serious error.
- If a storage node encounters a failure during the COMMIT phase of an XA transaction and cannot correctly recover those transactions, this may result in rollback of the transaction branches being committed at that time on this node. This could cause a situation where some branches of a global transaction are committed while others are rolled back, leading to data loss or inconsistency.
MySQL Transaction Failure Recovery Techniques in the Community Edition
Brief Introduction to Basic Concepts of MySQL Transaction Processing
To facilitate subsequent discussions, let's briefly go over some foundational knowledge and concepts of MySQL. If you're already familiar with these, feel free to skip ahead.
MySQL supports multiple storage engines and interfaces with them through its internally defined Handler interface. Currently, the most commonly used transactional storage engine is InnoDB, which is also the default storage engine for MySQL. Additionally, the MySQL community also utilizes MyRocks, a package that includes RocksDB and implements the HANDLER interface for the RocksDB storage engine, thus enabling MySQL to use RocksDB as another transactional storage engine.
MySQL transmits data updates to replica nodes via the binlog event stream. The replica node reprocesses these binlog events to mirror the data of the primary node, serving as an immediately available standby node for the primary, thus achieving high availability (HA). In MySQL, the binlog system is also considered a storage engine type, with the HANDLER interface implemented. However, the binlog system itself does not support transaction processing -- it cannot perform transaction rollback or recovery. When a binlog file exceeds a certain size, MySQL will automatically switch to a new binlog file, sequentially numbering these files in ascending order. Redundant binlog files can be purged by DBAs to free up storage space.
When the binlog system is enabled and gtid_mode is set to 'on', each MySQL transaction is uniquely identified by a global transaction identifier (GTIT), which includes the UUID of the primary node and a sequentially incrementing number assigned automatically by MySQL (this article does not discuss other edge cases of GTID). The system table, mysql.gtid_executed, meticulously keeps track of all GTIDs executed by a MySQL instance. Consequently, these three transaction sets must be identical for a MySQL instance, which is known as the MySQL Data Consistency Conditions:
The set of all transactions recorded in the binlog (although most of these will eventually be purged)
The set of transactions executed in the storage engine
The set of transactions associated with GTIDs recorded in mysql.gtid_executed
This is the objective of MySQL binlog recovery. For regular transactions, the MySQL community edition has achieved this goal. However, for XA transactions, the community edition completely ignores them, without any processing. In contrast, Kunlun-storage fully supports the failure handling of XA transactions, ensuring they also conform to the above consistency requirements.
The techniques mentioned in this article are based on the most common setting that provides the highest assurance of data consistency. This is also the setting that KunlunBase requires: enable binary logging, set gtid_mode=on, sync_binlog=1, and innodb_flush_at_trx_commit=1.
Transaction Processing Flow of the MySQL Community Edition
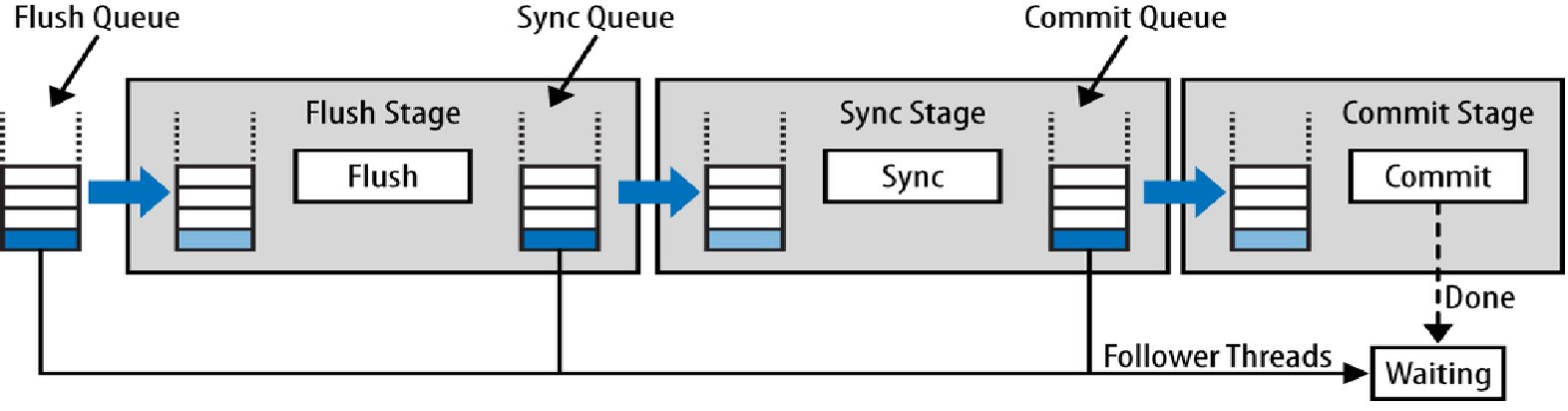
Illustration of Three-Stage Commit Pipeline for MySQL transaction
The MySQL community edition uses binlog for primary-replica replication to achieve high availability. This article describes the process of committing transactions when binlog is enabled, under asynchronous or semi-synchronous replication conditions. The fullsync feature in Kunlun-storage also adheres to this process.
To commit a transaction in MySQL, the transaction's binlog needs to be written into the binlog file, and the transaction's Write-Ahead Log (WAL) in each storage engine needs to be written into its respective transaction log file. This process, as illustrated above, is a three-stage commit pipeline. Before initiating this three-stage commit pipeline, each transaction first completes the engine prepare phase within their individual threads and flushes the redo log of transaction storage engines like InnoDB/MyRocks to persistent storage devices.
Attentive readers might have noticed that MySQL's transaction commit process also follows a two-phase commit mechanism, where it first prepares, then writes the binlog, and finally commits in the subsequent three-stage commit pipeline. The reason for this approach is that binlog effectively acts as a storage engine in MySQL, storing each transaction's data updates in the form of binlog events. Moreover, MySQL strives to maintain consistency between the set of transactions in the binlog and those in the actual transaction storage engines such as InnoDB.
This implies that the transaction storage engine must support a two-phase commit process. At present, both InnoDB and RocksDB support two-phase commit and can function as MySQL's transaction storage engines.
The Three-Stage Commit Pipeline for MySQL Transaction
MySQL replication logic requires that all binlog events of each transaction in the binlog be written to the binlog file sequentially. Once one transaction is completely written, the next transaction's binlog events are then written. Since MySQL-5.7 introduced GTID-based replication technology, the order of each transaction in the binlog needs to align with its GTID order. To achieve maximum concurrency while maintaining this order, MySQL employs a three-stage commit pipeline technique to carry out concurrent group commits of numerous transactions.
- Flush Stage
Firstly, several concurrent transactions enter the flush queue and obtain a GTID in their queue order. This GTID describes the commit order of these transactions and uniquely identifies a transaction (technically called an "event group", a minor difference that won't impact understanding; it will be elaborated on later) in the binlog within a MySQL primary-replica replication cluster (corresponding to KunlunBase storage cluster). This also forms the basis for parallel replication by replica nodes. Then, the leader thread in the queue sequentially flushes each transaction's binlog events (previously cached in its session) to the current binlog file. This ensures a strict alignment between the order of a transaction's binlog in the binlog file and its GTID order.
- Sync Stage
Upon completion of the flush stage, the transactions in the flush queue exit the queue collectively and enter the sync queue, freeing the flush queue for the next batch of transactions. Typically, for a heavily loaded MySQL instance, there are already transactions waiting to enter the flush queue. They begin the flush stage described above after entering the flush queue. Meanwhile, the transactions entering the sync queue are represented by their leader thread to perform one task -- sync the written binlog file. This process synchronizes the binlog file content written during the flush stage from the operating system's page cache to the disk, permanently storing this group of transactions' binlog on this server.
After the sync stage concludes, the transactions in the sync queue progress to the engine commit stage.
- Engine Commit Stage
As previously mentioned, prior to initiating the three-stage pipeline, the first action undertaken by the transactions in the commit process is to prepare the engine. At this point, these transactions still hold the PREPARED state within the transaction storage engine, so the engine commit stage finalizes the commit phase of these transactions within the transaction storage engine (InnoDB or MyRocks).
There are two ways to commit: either the transactions join the commit queue and the leader thread sequentially commits each one, or each transaction completes the commit independently within its own working thread. The choice between these two methods is controlled by the system variable 'binlog_order_commits'.
The advantage of committing in sequence by the leader thread (binlog_order_commits=true) is that it can achieve ultimate consistency. The order of each transaction's commitment, or the order in which other transactions can see the data updates of these committing transactions, is exactly the same as their order in the binlog. The drawback, however, is somewhat diminished performance, as the transactions are committed sequentially by a single thread, not leveraging the concurrency capabilities of multi-core CPUs and high-performance SSDs.
In contrast, independent commitment by each working thread (binlog_order_commits=false) takes full advantage of concurrency capabilities, yielding better performance. The disadvantage here is that the sequence of actual transaction commitments does not strictly align with their appearance in the binlog file. Nevertheless, this order difference is not an issue for the vast majority of scenarios. Therefore, in KunlunBase Kunlun-storage's configuration file template, we always set 'binlog_order_commits=false'.
Potential Risks Associated with MySQL Instance Failures
Without an effective transaction recovery mechanism, a malfunction in a MySQL instance could lead to situations where a transaction T, committed on the primary node, is either absent from the binlog while present in InnoDB, or vice versa. These inconsistencies can cause discrepancies between the primary and replica nodes, ultimately jeopardizing data consistency across them. As a consequence, data updates that are accurately executed on the primary node might fail when being replicated on the replica node. For instance, a row that is scheduled to be updated or deleted may not exist at all on the replica node, or a row that needs to be inserted could already be present on the replica node. These complications can stall primary-replica replication, preventing replica nodes from continuing to replicate updates from the primary node, thereby undermining the high-availability capacity of the MySQL primary-replica replication cluster.
When using GTID mode (gtid_mode=on), MySQL compares the executed GTID sets, denoted as Gtid_set_master and gtid_set_slave, when establishing primary-replica connections. MySQL requires that gtid_set_slave is a subset of gtid_set_master, otherwise it refuses to establish a primary-replica replication relationship. Consequently, the aforementioned discrepancies can impede the establishment of a primary-replica replication relationship, compromising the high availability of the cluster and potentially leading to data loss and service disruption following a primary node failure.
Thus, it is crucial to align the binlog with the transaction storage engine during MySQL server startup to satisfy the "MySQL Data Consistency Conditions." This process is referred to as binlog recovery.
For regular transactions (begin...commit transactions, or autocommit statement transactions), the MySQL community edition can correctly complete binlog recovery. However, for XA transactions, the MySQL community edition does not accurately implement XA PREPARE nor performs any binlog recovery operations, which can lead to a series of problems. The following sections detail these aspects and elaborate on the improvements and enhancements made by the KunlunBase team in managing MySQL XA transactions.
Binlog Recovery Process for Regular Transactions in the MySQL Community Edition
During storage node failure, any active transactions that haven't reached the prepare phase are entirely rolled back by the transaction storage engine during mysqld startup, and they do not exist at all in the binlog file. Hence, these transactions do not cause any issues. If a transaction has already gone through the entire commit process at the time of failure, this transaction will be accurately restored by the storage engine, and no further action is required.
For transactions that are in the midst of being committed, they might be in the engine prepare phase, flush phase, sync phase, or commit phase. If a transaction has completed the sync phase, or the flush phase and the server OS has not restarted, then its binlog will definitely be present during failure recovery, and the transaction can be committed; otherwise, it must be rolled back. This is the transaction recovery work to be done during the binlog recovery phase.
For regular transactions, the MySQL community edition can correctly perform binlog recovery operations. The process involves:
- Fetching the GTID set of all transactions that have appeared in all binlog files prior to the last binlog file (denoted as LB) from LB's prev_gtids_log_event (This set is termed as S0).
- Scanning LB to derive the GTID set of all transactions within LB (This set is referred to as S1).
- Calculating the GTID set of all transactions executed in this MySQL instance, S = S0 + S1.
Then, for every transaction storage engine (InnoDB, MyRocks), denoted as TXN_SE:
Obtain the set of all transactions in the prepared state recovered by TXN_SE, referred to as txns_prepared.
For each transaction, txn, in txns_prepared, if txn.gtid resides in S (implying that txn's binlog is present in the binlog file), commit txn; otherwise, roll back txn.
This ensures that for every transaction, txn, in the PREPARED state in TXN_SE, if txn does not exist in the binlog, then txn will be rolled back in TXN_SE; if txn exists in the binlog, then txn will be committed in TXN_SE. Consequently, after mysqld starts, all recovered regular transactions adhere to the "MySQL Data Consistency Conditions."
Deficiencies in MySQL Community Edition's XA Transaction Processing and Its Fixes in Kunlun-Storage
The MySQL community edition has several issues concerning the XA transactions. These will be discussed one by one in this section. Given the severe potential risks highlighted earlier, it is necessary to enhance and improve MySQL's error handling and fault recovery capabilities for XA transactions. Consequently, Kunlun-storage will be able to accurately restore XA transaction branches, enabling KunlunBase at the cluster level to precisely recover global transactions that were in the process of being committed at the point of failure. The most critical part of recovery is that the storage node must correctly restore its local XA transaction branch.
Incorrect Timing for XA PREPARE Write to Binlog
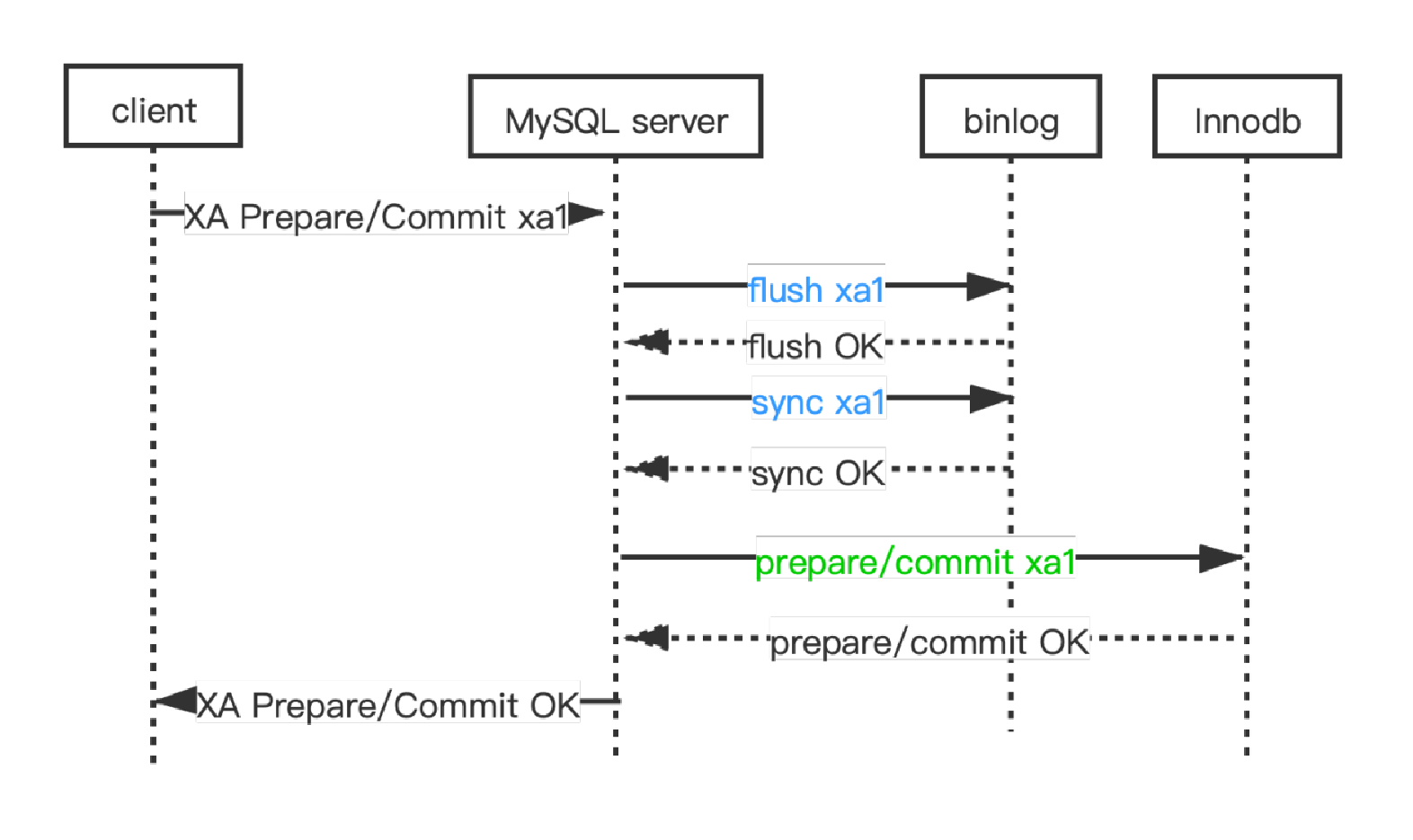
XA PREPARE and XA COMMIT processing flow in MySQL community edition
The process depicted above outlines the execution of XA PREPARE in the MySQL community edition. It initially flushes and syncs binlog within the three-stage commit pipeline, and then executes the engine prepare.
The problem with this approach is that if all binlog events of this XA transaction, xa_txn1, have been completely transmitted to the replica node between the flush & sync binlog and the completion of engine prepare, and then mysqld on the primary node exits due to various software and hardware faults, upon restart of mysqld, xa_txn1 is absent in InnoDB and other transaction storage engines. However, xa_txn1 is present in the binlog of the primary node and also exists in the replica node of this primary node. In other words, the primary and replica data are inconsistent, violating the "MySQL Data Consistency Conditions". Therefore, it is a serious error.
The solution is to adjust the timing of the flush & sync binlog in XA PREPARE: only after all transaction storage engines have finished preparing is the XA transaction's binlog flushed & synced. Yet, rearranging the order in this way leads to a new issue -- the clone function ceases to work.
The Execution Flow of XA PREPARE in Kunlun-Storage and the Support for Clone Function
Kunlun-storage does not rely on the clone function because, currently, only InnoDB supports clone and other storage engines do not. For physical backups, Kunlun-storage still employs XtraBackup. Nevertheless, we have decided to refine InnoDB clone's support for XA transactions to ensure the integrity of Kunlun-storage's functionality.
Clone requires that without binlog transmission, the set of GTIDs stored in the mysql.gtid_executed table on the new node is equivalent to the set of GTIDs of all transactions executed by this MySQL instance. That is:
For any transaction t, t is in InnoDB <=> t.gtid is in the mysql.gtid_executed table.
This is one of the conditions in the "MySQL Data Consistency Conditions".
To fulfill this, MySQL stores the transaction's GTID in the InnoDB undo log during transaction commit, and a background thread, gtid_persistor, can subsequently flush this GTID into the mysql.gtid_executed table. The new instance obtained by clone contains all the valid undo logs of the source instance, so its gtid_persistor can merge GTID into the mysql.gtid_executed table, thereby satisfying the "MySQL Data Consistency Conditions." For this purpose, the InnoDB purge thread will only purge the undo log of a transaction after its GTID has been flushed to the mysql.gtid_executed table.
After adjusting the internal execution order of XA PREPARE, i.e., engine prepare is now executed before binlog flush & sync, the transaction's GTID is not generated yet at the time of executing InnoDB prepare, because the GTID can only be generated after entering the flush queue of the three-stage pipeline. Therefore, in Kunlun-storage, we do not write GTID into its undo log when executing the InnoDB prepare of an XA transaction. Instead, after entering the flush queue and obtaining the GTID, the GTID of each transaction is written into its InnoDB undo log in turn. Finally, after the sync phase is completed, the GTID is handed over to be merged into the mysql.gtid_executed table (the reason for this step will be detailed later). The figure below illustrates this process.
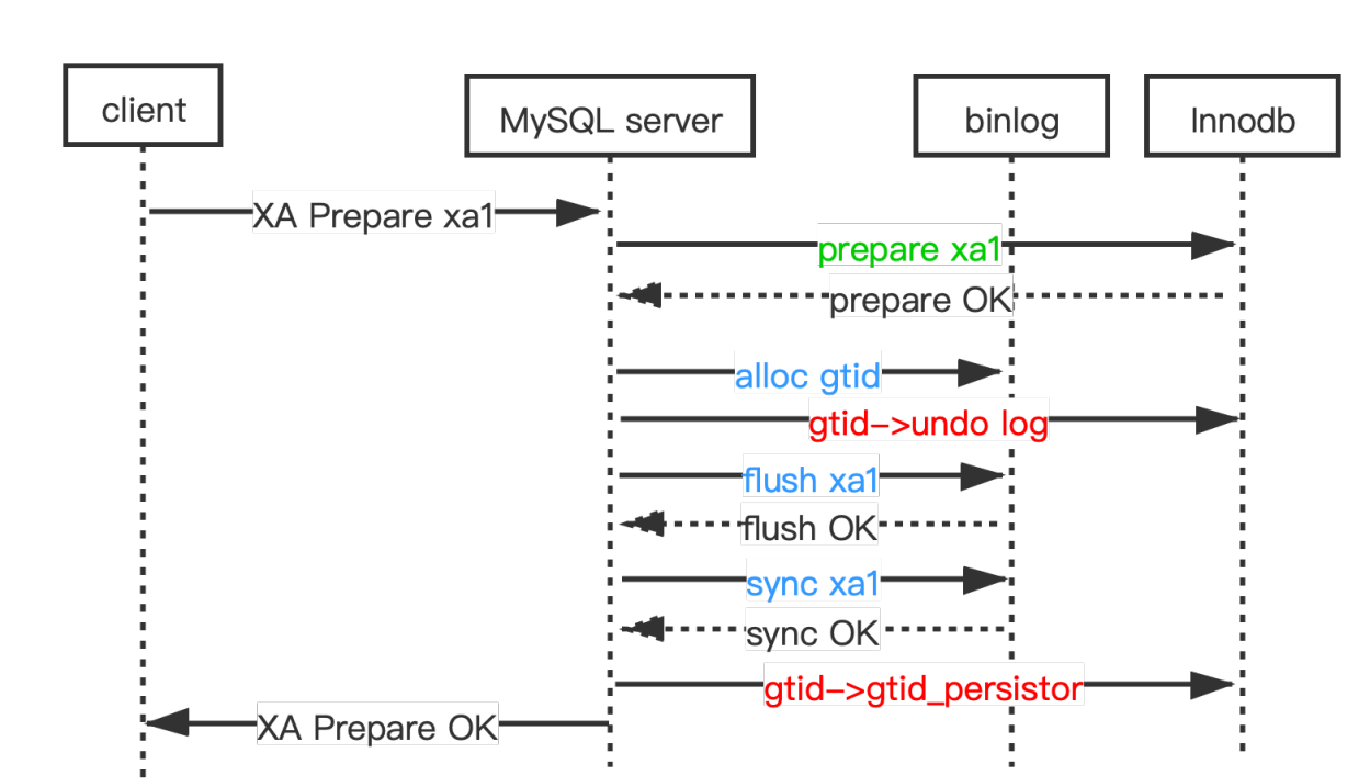
Illustration of the XA PREPARE process in Kunlun-storage
MySQL Community Edition Does Not Record XA Transactions in PREPARED State in Binlog
In MySQL, the two phases of an XA transaction are recorded in binlog as two different binlog event groups (BEG), each with a unique GTID, even if the two phases of the same XA transaction have different GTIDs for their BEGs. Moreover, these two BEGs may be distributed in two separate binlog files. This means that if we aim to locate all binlog entries of XA transactions in the PREPARED state, we have to traverse all binlog events in all binlog files, which will bring huge IO and computational load. Worse yet, if obsolete binlog files are purged, we may mistakenly roll back XA transactions that should remain in the PREPARED state because we cannot find their binlog, according to the algorithm described in the previous section.
Kunlun-storage solves this problem by recording the set of XA transaction IDs in the PREPARED state in the current instance in the prev_gtid_log_event at the head of each binlog file. In this way, during binlog recovery, we simply need to open the last binlog file, and combine the set of XA transaction IDs recorded in its the prev_gtid_log_event (X0) with the set of XA transaction IDs composed of all XA_PREPARE_log_event events found in the last binlog file (X1) to derive the set X_prepared. Concurrently, while scanning the last binlog file, Kunlun-storage logs all XA COMMIT and XA ROLLBACK event XA transaction IDs to X_committed and X_aborted sets respectively. These three sets are then utilized during Kunlun-storage's binlog recovery process.
Kunlun-storage's Approach to XA Transaction Failure Recovery
Firstly, during InnoDB's startup recovery process, if an XA transaction requires a GTID but its undo log does not contain a GTID, the transaction will be rolled back.
During binlog recovery, while restoring each transaction in the PREPARED state returned by the storage engine, the following recovery steps are needed for XA transaction xa_txn1:
The XA transaction ID of xa_txn1 (hereinafter referred to as xa_txn1.xa_txn_id) is used to search the X_prepared set. If it is not found (i.e., the first phase binlog of xa_txn1 does not exist in the binlog file), which essentially means that xa_txn1.gtid is not present in the S set described earlier, then xa_txn1 has not completed the XA PREPARE stage. However, unlike regular transactions, XA transactions can commit in either one or two phases, the mode of which is decided by GTM, as explained in the previous sections. Thus, if xa_txn1 is a one-phase commit transaction, the binlog recovery process will check if xa_txn1.xa_txn_id is present in X_committed. If it is, xa_txn1 will be committed. Except for the above scenario, in all other cases where xa_txn1 neither completes XA prepare nor the binlog flush & sync of one-phase commit, but only completes the engine prepare operation of these two operations, xa_txn1 will be rolled back.
After the sync phase is completed, xa_txn1's XA PREPARE is sure to be executed, because once the sync is completed, this BEG must exist in the binlog, and exist in transaction storage engines such as InnoDB (although it might get rolled back in the second phase). Therefore, handing over the GTID to the gtid_persistor after the sync phase is completed can ensure that every GTID in the mysql.gtid_executed table definitely belongs to a transaction executed in the storage engine and has existed in the binlog as an event group.
If xa_txn1.xa_txn_id is found in X_committed, then commit xa_txn1; otherwise, if xa_txn1.xa_txn_id is found in X_aborted, then roll back xa_txn1. Otherwise, keep xa_txn1 in the PREPARED state. These transactions will be handled subsequently (commit or rollback) by the cluster_mgr of KunlunBase.
The reason why the second phase BEG of xa_txn1 can be found while xa_txn1 remains in the PREPARED state is that both MySQL community edition and Kunlun-storage execute binlog flush & sync prior to the engine commit in the XA COMMIT and XA ROLLBACK process. This method is correct. However, if the MySQL instance fails between the writing of binlog and the completion of engine commit, upon reboot, the second phase binlog of xa_txn1 will be found in the binlog file, but xa_txn1 is still in the PREPARED state. While MySQL community edition cannot recover XA transactions, Kunlun-storage can recover them correctly.
Conclusion
With the improvements and enhancements made to the transaction failure handling process of MySQL community edition, the KunlunBase cluster, powered by Kunlun-storage, can accurately handle failures of any node in the cluster and ensure the ACID properties of all transactions successfully committed within the KunlunBase cluster. For a shard with 2*N+1 nodes, the KunlunBase cluster can guarantee data integrity, prevent data loss, and continue to provide data read and write services even when N storage nodes fail simultaneously. The capability of Kunlun-storage to handle XA transaction failures constitutes a significant pillar of KunlunBase's financial-grade high reliability technology system. It is a crucial part of KunlunBase's core technology system, and a significant enhancement and extension to MySQL community edition.