
五、如何同步 MySQL 数据到 KunlunBase(原KunlunBase)
五、如何同步 MySQL 数据到 KunlunBase(原KunlunBase)
本文介绍如何从一个运行中的 MySQL 实例同步全量数据到 Klustron 集群然后持续地流式同步数据更新到这个 Klustron 集群。
01 修改 mysql 实例权限
- mysql 实例要有 spuer 或者 BACKUP_ADMIN 权限,不然 mydumper 导出的 metadata 文件无 Pos 值及 Log 值
mysql -u root -proot -P 8898 -h 172.0.0.132
GRANT Super, BACKUP_ADMIN ON *.* TO 'root'@'%' WITH GRANT OPTION;
flush privileges
02 使用 mydumper 全量导出 MySQL 数据
- 在 Klustron 集群 base 目录下 kunlun-node_mgr 包的 bin/util/ 里有该工具,使用 mydumper 把 mysql 的数据导出到指定位置下
./mydumper -h 172.0.0.136 -u root -p root -P 8898 -B sysbench -o /nvme2/compare/sysbench/mydumper

- -B 要导出的数据库
- -o 导出文件所存放的位置
03 ddl2kunlun-linux
从klustron-1.2 开始,不再需要此步骤,因为klustron-1.2 的计算节点已经可以执行MySQL 专有的常用 DDL语法。
- 下载
wget http://downloads.Klustron.com/kunlun-utils/1.1.1/ddl2kunlun-linux
- 该工具是用来把 mysql 的表定义转化成可以被 Klustron 使用的表定义
- 使用示例
./ddl2kunlun-linux -host="172.0.0.132" -port="8898" -user="root" -password="root" \
-sourceType="mysql" -database="tpcc" -table="tablename" > a.sql
-host -port -user -password被导出的数据库的信息-sourceType被导出的数据库的数据库类型,默认mysql-database -table要导出的数据库及表名可以通过
./ddl2kunlun-linux --help查看帮助文档随后使用 psql 或者 mysql 将导出的表定义导入到 Klustron 里生成表
然后使用命令行在 Klustron 里产生对应表
PGPASSWORD=abc psql -h 172.0.0.113 -p 47001 -U abc -d postgres < a.sql也可以使用一个 for 循环完成整个过程, 以单个sysbench 库为例
echo `show tables;` > sysbench.sql
for i in `mysql -h 172.0.0.132 -uroot -proot -P8898 sysbench < sysbench.sql | grep -v Tables_in_`
do
./ddl2kunlun-linux -host="172.0.0.132" -port="8898" -user="root" -password="root" -sourceType="mysql" -database="sysbench" -table="$i" > a.sql
echo create table $i
psql -h 172.0.0.132 -p 35001 -U abc -d postgres < a.sql
done
04 处理 mydumper 产生的 sql 文件
- 如果使用的是 Klustron mysql 协议则不需要做这一步
- 在 Klustron pg 协议中,"" 双引号会被识别成 column
- 日期有最小值,1970-01-01
cd /nvme2/compare/sysbench/mydumper
for i in `ls . | grep -v schema | grep sql`
do
table=`echo $i | awk -F. '{print $2}'`
db=`echo $i | awk -F. '{print $1}'`
sed -i "s/\`$table\`/${db}.$table/" $i
sed -i 's/0000-00-00/1970-01-01/' $i
sed -i "s/\"/'/g" $i
done
05 把处理过的 mydumper 数据导入到 Klustron
- 主要是导入像
sysbench.customer.00000.sql这个文件名的 sql 文件,其它的如文件名包含有metadata和schema的都不用导入 Klustron
PGPASSWORD=abc psql -h 172.0.0.132 -p 30001 -U abc -d postgres -f sysbench.customer.00000.sql
- 可以参考以下脚本快速导入
cd /nvme2/compare/sysbench/mydumper
for i in `ls . | grep -v schema | grep sql`
do
PGPASSWORD=abc psql -h 172.0.0.132 -p 30001 -U abc -d postgres -f $i
done
06 binlog2sync
从Klustron-1.2版本开始,不再需要本步骤 --- 用户无需使用binlog2sync工具,可以直接使用Klustron CDC工具来持续流式导入持续运行的MySQL 实例中的数据更新操作到Klustron集群, 实现实时流式数据同步。
- 下载
wget http://downloads.Klustron.com/kunlun-utils/1.1.1/binlog_sync
- binlog2sync 把上游 mysql 数据库的 binlog 转成 sql 语句送给下游的 Klustron 集群,它会流式地持续读取binlog 并持续输出SQL语句给klustron的目标计算节点。
- 在使用前要修改上游数据库的参数:
set global binlog_row_metadata = FULL;
选项详解:
--remote_host,--remote_port,--remote_user,--remote_password分别是上游数据库的 ip,port,user,pwd ;--remote_binlog_file使用 mydumper,会在指定或者当前目录下产生一个 metadata 文件,里面的Log对应这个选项;--binlog_position使用 mydumper,会在指定或者当前目录下产生一个metadata文件,里面Pos对应这个选项;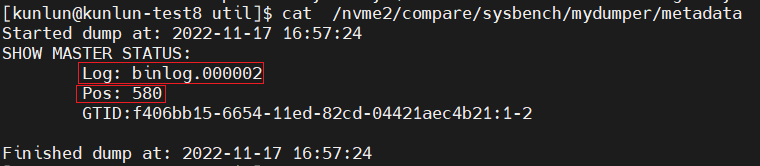
--db_host,--db_port,--db_user,--db_password下游 Klustron 中 mysql 协议的计算节点的 ip,port,user,pwd;--job_id随便填个数字就行;--db_type写入节点用的是 mysql 协议还是 postgres 协议,Klustron 用 postgres;--stop_never当值为 1 时,在同步到最新 binlog 位置时,该程序不会停止。当值为 0 时,反之在同步到最新 binlog 位置时,该程序会停止。示例
./binlog_sync --remote_host=172.0.0.136 --remote_port=8898 --remote_user=root --remote_password=root --remote_binlog_file=binlog.000002 \
--binlog_position=120404375 --db_host=172.0.0.132 --db_port=30002 --db_user=abc --db_password=abc --reserve_event_dir=./binlog_event \
--db_type="postgres" --work_mode="stream" --stop_never_server_id=100 --stop_never=1 > log 2>&1 &