
Klustron(原KunlunBase) 读写分离方案
Klustron(原KunlunBase) 读写分离方案
Klustron 数据库集群在数据库内部支持读写分离,并且对应用透明,用户应用程序不需要做任何修改就可以使用数据库的读写分离功能,从而大幅提高整个系统性能及硬件利用率。
一、概述
Klustron 的整体架构主要由计算层和存储层构成,计算层负责 SQL 响应、解释、执行等,存储层负责数据的存储管理,存储层的数据采用多副本存储机制,备机(从副本)通过KlustronDB特有的全同步(fullsync)技术保持数据与主节点一致性。
在一般的生产使用过程中,Klustron集群各个shard的备机节点的主要目的是在其主节点出现故障后,被Klustron自动升级为新的主节点,在备机角色时不接受应用程序的直接数据处理请求。因此,备机的存储节点的硬件配置通常应该与主节点一致,以便可以在需要时升级为主节点并具备足够的硬件资源;同时这意味着在非故障切换的情况下,备机的存储节点资源利用率相对较低。
Klustron 具备透明的自动的读写分离能力,以便充分 利用所有备机的硬件资源,提供尽可能高的性能。Klustron的计算节点能够自动透明地发送只读操作到目标shard的备节点,从而可以大幅减少只读查询对shard主节点的资源竞争和消耗,降低主节点负载从而提升其吞吐率并降低各种语句的平均执行时间,提升集群整体的吞吐率和性能。
二、实现原理
Klustron 的读写分离在计算节点的分布式查询处理器来控制和执行。Klustron会自动检查用户的SQL语句是否同时满足如下条件,如果满足则自动对该语句启用读写分离。
- 当前 SQL 类型为 select;
- SQL 中不包含用户自定义函数(即 create function 语句创建的函数),除非当前事务被显式标记为只读事务;
- 如果不在显式事务中( autocommit=on ),则允许读写分离;如果语句在显式事务中,则要满足:
- 如果在只读事务中,则允许读写分离;
- 如果在读写事务中,则该事务尚未更新过任何数据;
分布式查询优化器就会将相应的数据读取命令下发到目标shard的某个备节点上执行。
KlustronDB 会根据以下规则选择发送select语句到目标存储集群的哪个备节点:
- 根据一个shard的每个存储节点权重值选择 (ro_weight),权重大的优先;
- 根据网络延迟(ping),即该shard主备节点间网络数据包的延迟,优先选择延迟较小的备节点;
- 根据该shard各个备节点的复制(replication)的延迟(latency),优先选择复制延迟较小的备节点;
三、配置实施
典型场景:某 OLTP 业务系统有大量的查询操作,在业务高峰期数据库响应速度变慢,导致了业务的性能问题。经检查发现存储节点主节点的存储节点的 IO 资源利用到达瓶颈,但备机节点的 IO 资源利用率低。
以上场景可以通过读写分离方案解决系统性能问题,不需要修改应用, 不需要增加硬件配置,通过读写分离的实施,可以解决性能问题。
使用方法:
第一步:设置参数,启用读写分离
用以下几种方法之一来打开读写分离开关。根据实际需求和场景选一种级别。
- 在数据库会话中打开读写分离开关
该设置仅在该会话的生命期和范围内有效,在其他会话中无效,并且该会话结束后,该设置即失效。
set enable_replica_read = on -- (on 开启读写分离, off 关闭)。
- 用户级别开启
该用户每次重新登录这个KlustronDB集群的任何一个计算节点后,此设置都仍然在该用户的所有会话中都有效。即使该计算节点重启后也有效。
alter user abc set
enable_replica_read = true;
- 计算节点级别开启
在 配置文件中做如下设置然后保存配置文件然后重启这个计算节点或者重新加载配置文件。此方法设置后对该计算节点的所有session有效,即使该计算节点重启后也有效。但是对本集群的其他计算节点无效。
enable_replica_read=on
- 全集群范围内对所有用户开启
此方法对本集群现有的所有用户以及未来创建的所有用户都生效。对于这个KlustronDB集群的任何一个计算节点的所有会话都有效。
alter system set
enable_replica_read = true;
第二步:登录数据库,配置读写分离策略。
设置如下参数,启动读写分离策略:
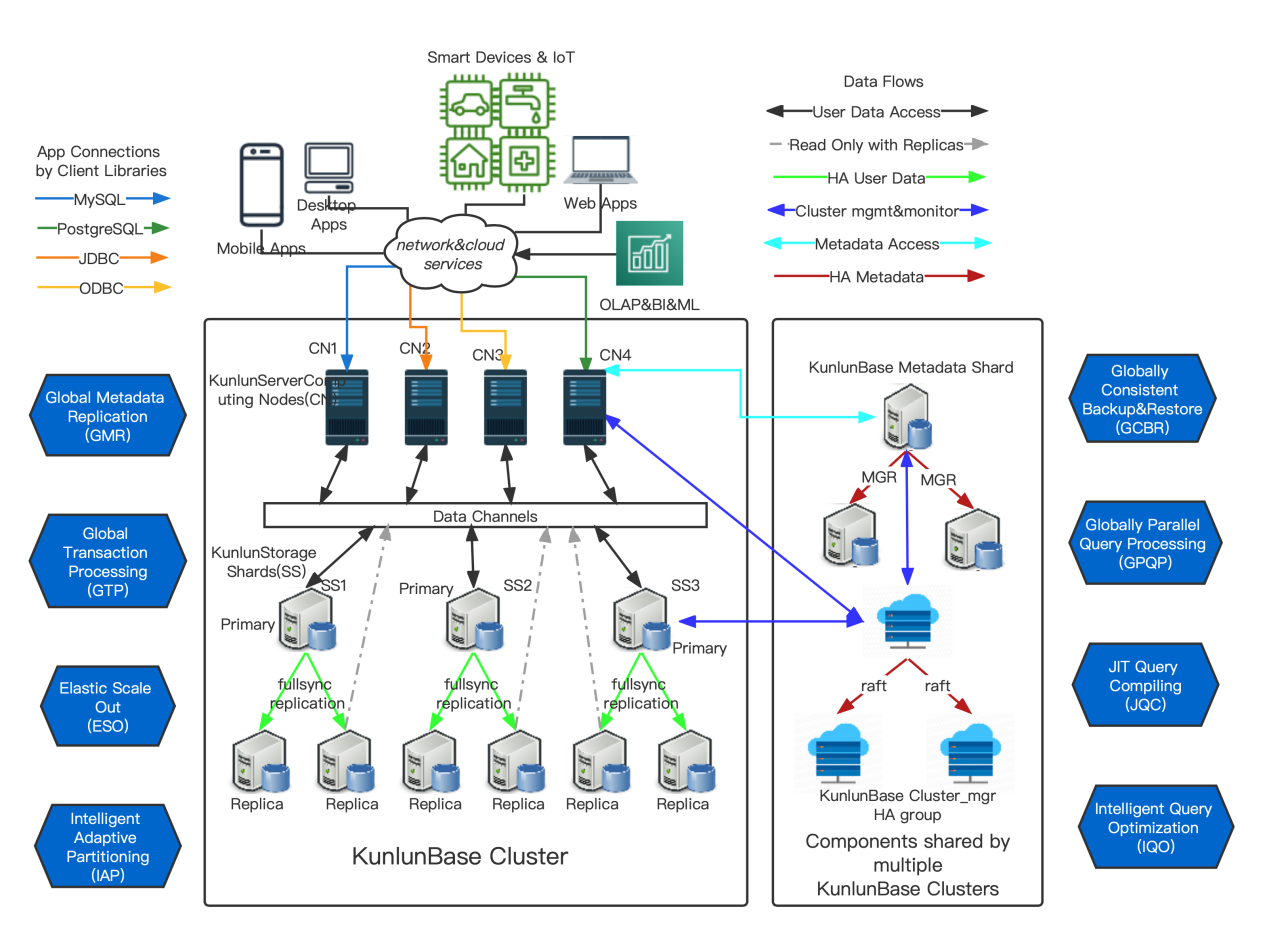
replica_read_ping_threshold- 计算节点到备节点的ping延迟阈值,大于此阈值则不使用此备节点。0 表示不考虑此因素;
replica_read_latency_threshold- 主备同步延迟的阈值,大于此阈值则不使用备节点。0 表示不考虑此因素;
replica_read_order,选择备机优先级:0,按权重;1、按ping延迟;2、按主备同步延迟;- 如果第一优先的条件已经可以得到最合适的备节点,就使用它;如果得到多个最优,再考虑剩余的选择条件。
replica_read_fallback备机选择的回退策略,即如果备机不能访问时,应该怎么办。有以下选项:
replica_read_fallback=0,直接报错replica_read_fallback=1,任意选择一个备机进行访问replica_read_fallback=2,选择目标shard的主节点读取本次查询所需数据
第三步:检查&设置权重(可选)。
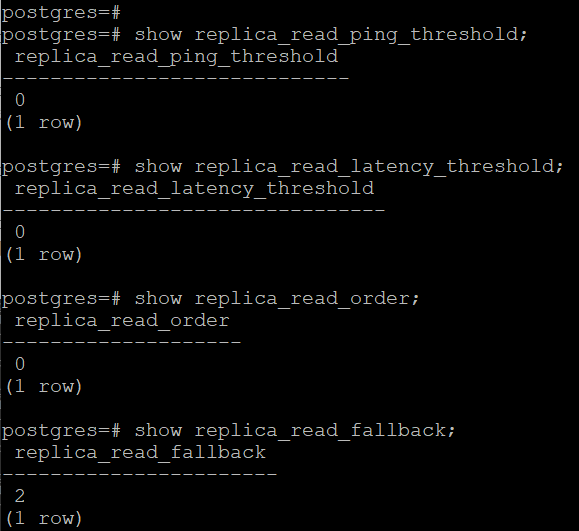
在本文的集群环境中 ,KlustronDB数据库集群由两个 shard 组成(shard1 , shard2) ,shard1 的shard_id=1, shard1 包含3个副本(id 为1,2, 3,id为1的是主节点,id 为 2 和 3 的是备机。
通过配置, 可以设置只读操作的首选备机
设置 Shard1 的 node3 主机的作为首选备机(因为 node2 节点位于不同机房,延迟太高):
update pg_shard_node set ro_weight=2 where
port=6006;
Select * from pg_shard_node ;
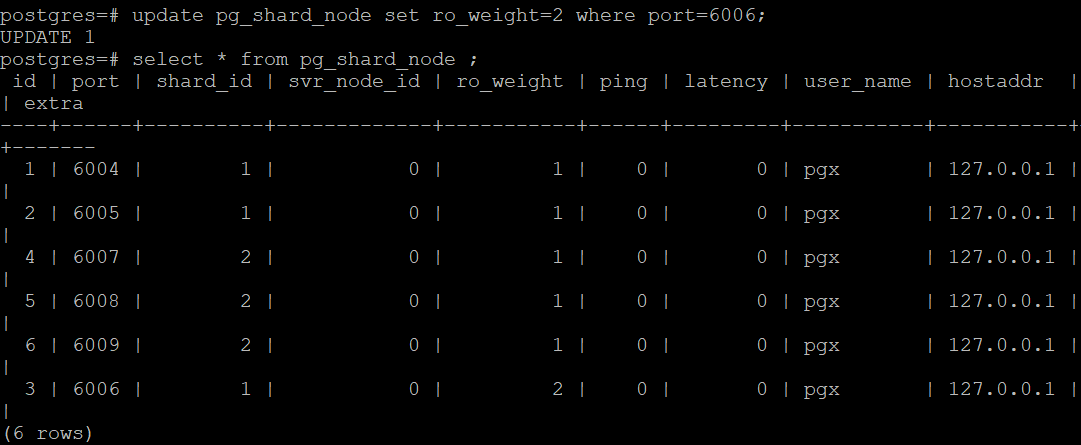
Shard1 的 node3 的权重最高(ro_weight=2)
第四步:执行查询,验证读写分离(可选)。
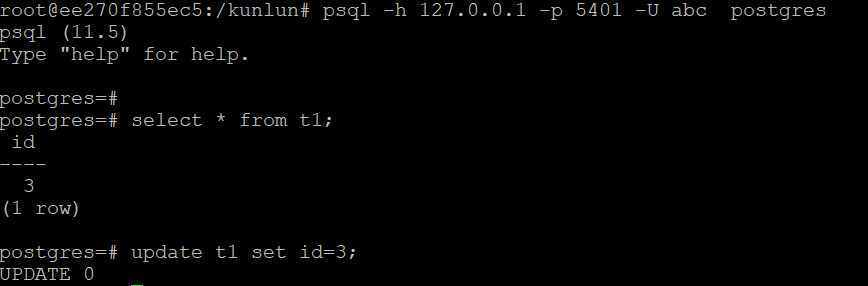
通过设置log_min_messages to ‘debug1’ 可以将 SQL 语句的执行信息输出到日志中, 以方便检查 SQL 下发的目标存储节点(生产系统不要这样设置,否则影响性能)。
查看计算节点的日志,确认读写分离。 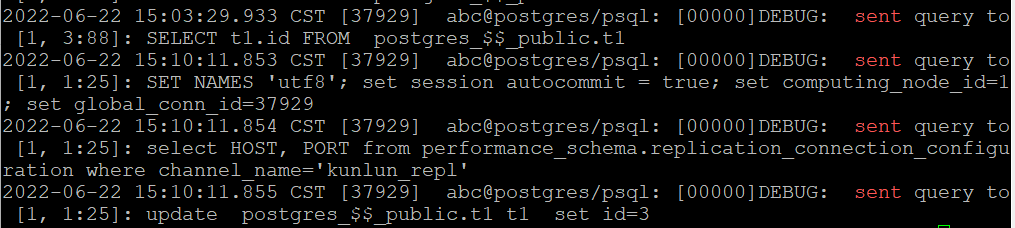
从日志中可见SQL 只读语句(select ti.id from t1) 被下发到 shard1,节点 3 上(该副本权重最高), 而update 语句(update t1 set id=3) 是在主节点 shard1 节点 1 上执行。
结论
以上过程验证了该用户的读写操作分离实现。只读语句将被路由到从备机节点,降低了主节点的 IO 资源利用率,系统整体性能获得提升。